Что Вы рекомендовали бы для интенсивного трафика ajax интенсивному веб-сайту?
Ниже кода, который я написал, чтобы сделать это. Это работает в моей системе.
foreach ($mbx in Get-Mailbox -ResultSize unlimited) {
Get-MailboxFolderStatistics -Identity $mbx | Where-Object { Ниже кода, который я написал, чтобы сделать это. Это работает в моей системе.
[110] Вместо того, чтобы сначала назначать все объекты почтового ящика переменной, используется оператор foreach с Get-Mailbox в нем. Когда вы начнете администрировать систему Exchange с тысячами почтовых ящиков, вы поймете, почему это лучше
.FolderType -eq 'Calendar'} | ForEach-Object {
$path = "$($MBX.Alias):$( Ниже кода, который я написал, чтобы сделать это. Это работает в моей системе.
[110] Вместо того, чтобы сначала назначать все объекты почтового ящика переменной, используется оператор foreach с Get-Mailbox в нем. Когда вы начнете администрировать систему Exchange с тысячами почтовых ящиков, вы поймете, почему это лучше
.Folderpath)".Replace('/','\')
$DefaultPermission = Get-MailboxFolderPermission -Identity $path -User Default
if ($DefaultPermission.AccessRights -notcontains 'PublishingEditor') {
Set-MailboxFolderPermission -Identity $path -AccessRights PublishingEditor -User Default
}
else {
Write-Host 'Already Done'
}
}
}
Вместо того, чтобы сначала назначать все объекты почтового ящика переменной, используется оператор foreach с Get-Mailbox в нем. Когда вы начнете администрировать систему Exchange с тысячами почтовых ящиков, вы поймете, почему это лучше
5 ответов
Я не могу говорить с вопросом MySQL/PostgreSQL, поскольку я ограничил опыт с Пост-ГРЭС, но мой исследовательский проект Masters был о высокоэффективных веб-сайтах с CherryPy, и я не думаю, что Вы будете разочарованы при использовании CherryPy для сайта. Это может легко масштабироваться тысячам одновременных пользователей на потребительском оборудовании.
Конечно, то же могло быть сказано для PHP, и я не знаю ни о каких разумных сравнительных тестах, сравнивающих работа CherryPy и PHP. Но если Вы задавались вопросом, может ли CherryPy обработать сайт интенсивного трафика с огромным количеством запросов в секунду, ответ - определенно да.
Идеальная установка была бы близко к этому:
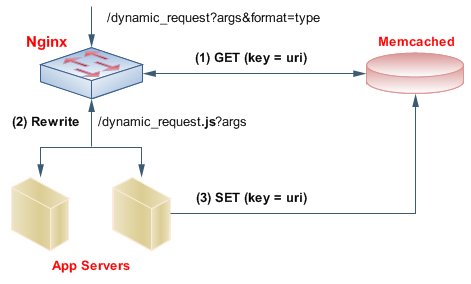
Короче говоря, nginx является быстрым и легким webserver/front-proxy с уникальным модулем который, позвольте нам, он выбирает данные непосредственно из хранилища RAM memcached, не поражая диск или любое динамическое веб-приложение. Конечно, если URL запроса уже не кэшировался (или если он истек), запрос продолжается к веб-приложению, как обычно. Часть гения - то, что, когда веб-приложение генерировало ответ, копия его переходит к memcached, готовому быть снова использованным.
Все это совершенно применимо не только к веб-страницам, но и к запросу/ответам Ajax.
в статье 'задние' серверы являются http и конкретно говорят о полукровке. Было бы еще лучше, если бы спиной был FastCGI и другой (быстрее?) платформа; но это намного менее очень важно, так как nginx/memcached команды поглощают самую большую часть загрузки.
обратите внимание, что, если Ваша схема URL трафика Ajax хорошо разработана (REST лучший, по моему скромному мнению), можно исправить большую часть DB в memcached и любой POST (который передаст приложению), может заблаговременно обновить кэш.
По вопросу о DB я сказал бы, что PostgreSQL масштабируется лучше и имеет лучшую целостность данных, чем MySQL. Для небольшого сайта MySQL мог бы быть быстрее, но от того, что я услышал, он значительно замедляется, когда размер базы данных растет. (Отметьте: я никогда не использовал MySQL для большой базы данных, таким образом, необходимо, вероятно, получить второе мнение о его масштабируемости.), Но PostgreSQL определенно масштабируется хорошо и был бы хорошим выбором для сайта интенсивного трафика.
Испытание необходимость в большем количестве данных. У Jeff было несколько статей о тех же проблемах, и ответ должен был ожидать, пока Вы не поражаете проблему производительности.
запускаться с - кто размещает и что они имеют в наличии? что такое Ваш в наборах навыков таланта дома? Будут Вами нанимающий внешнюю фирму? что они рекомендуют? совершенно новый проект w/команда, готовая изучить новую платформу?
2-я вещь состоит в том, чтобы сделать некоторые макеты - как интерфейс собирается работать. какие данные это должно загрузить и сохранить? идея состоит в том, чтобы сохранить Ваш трафик между сетью и стороной дб вниз. например, никакие болтливые страницы с большим количеством запросов. и т.д.
После того как у Вас есть лучшая идея требований к данным, и поток - затем работают над проектированием баз данных. существует много правил следовать, но один из лучших должен следовать за правилами нормализации (да, я - парень дб почему?)
Теперь у Вас есть сборка на несколько страниц - запускает Ваши тесты. у Вас есть проблема? Да, теперь посмотрите на то, что это. Обслуживание страницы или получения по запросу дб? Мера затем выбирает план действий.