Сведение мелкого списка в Python [дубликат]
9 ответов
Если Вы просто надеетесь выполнять итерации по сглаженной версии структуры данных и не нуждаетесь в индексируемой последовательности, рассматриваете itertools.chain и компания .
>>> list_of_menuitems = [['image00', 'image01'], ['image10'], []]
>>> import itertools
>>> chain = itertools.chain(*list_of_menuitems)
>>> print(list(chain))
['image00', 'image01', 'image10']
Это будет работать над чем-либо, что это повторяемо, который должен включать Django, повторяемого QuerySet с, которая кажется, что Вы используете в вопросе.
Редактирование: Это, вероятно, столь же хорошо как уменьшение так или иначе, потому что уменьшают, будет иметь то же служебное копирование объектов в список, это расширяется. chain только подвергнется этим (тем же) издержкам, если Вы будете работать list(chain) в конце.
Метаредактирование: На самом деле, это - меньше служебное, чем предлагаемое решение вопроса, потому что Вы выбрасываете временные списки, которые Вы создаете при расширении оригинала с помощью временного файла.
Редактирование: Как J.F. Sebastian говорит itertools.chain.from_iterable, избегает распаковки, и необходимо использовать это для предотвращения * волшебство, но timeit приложение показывает незначительное различие в производительности.
Что относительно:
from operator import add
reduce(add, map(lambda x: list(x.image_set.all()), [mi for mi in list_of_menuitems]))
, Но, Guido рекомендует против выполнения слишком много в одной строке кода, так как это уменьшает удобочитаемость. Там минимально, если таковые имеются, увеличение производительности путем выполнения того, что Вы хотите в одной строке по сравнению с несколькими строками.
В Python 2.6, с помощью chain.from_iterable() :
>>> from itertools import chain
>>> list(chain.from_iterable(mi.image_set.all() for mi in h.get_image_menu()))
Это старается не создавать промежуточного списка.
Результаты проверки производительности. Пересмотренный.
import itertools
def itertools_flatten( aList ):
return list( itertools.chain(*aList) )
from operator import add
def reduce_flatten1( aList ):
return reduce(add, map(lambda x: list(x), [mi for mi in aList]))
def reduce_flatten2( aList ):
return reduce(list.__add__, map(list, aList))
def comprehension_flatten( aList ):
return list(y for x in aList for y in x)
я сгладился, 2-уровневый список 30 объектов 1000 раз
itertools_flatten 0.00554
comprehension_flatten 0.00815
reduce_flatten2 0.01103
reduce_flatten1 0.01404
Уменьшают, всегда плохой выбор.
Вот правильное решение с помощью пониманий списка (они являются обратными в вопросе):
>>> join = lambda it: (y for x in it for y in x)
>>> list(join([[1,2],[3,4,5],[]]))
[1, 2, 3, 4, 5]
В Вашем случае это было бы
[image for menuitem in list_of_menuitems for image in menuitem.image_set.all()]
, или Вы могли использовать join и сказать
join(menuitem.image_set.all() for menuitem in list_of_menuitems)
В любом случае, глюк был вложением эти for циклы.
Первое, что пришло на ум можно устранить лямбду:
reduce(list.__add__, map(list, [mi.image_set.all() for mi in list_of_menuitems]))
Или даже устраняют карту, так как Вы уже получили аккомпанемент списка:
reduce(list.__add__, [list(mi.image_set.all()) for mi in list_of_menuitems])
можно также просто выразить это как сумму списков:
sum([list(mi.image_set.all()) for mi in list_of_menuitems], [])
Это решение работает на произвольные глубины вложения - не только "список списков" глубина что некоторые (все?) других решений ограничены:
def flatten(x):
result = []
for el in x:
if hasattr(el, "__iter__") and not isinstance(el, basestring):
result.extend(flatten(el))
else:
result.append(el)
return result
Это - рекурсия, которая допускает вложение произвольной глубины - пока Вы не поражаете максимальную глубину рекурсии, конечно...
У Вас почти есть он! способ сделать вложенные понимания списка состоят в том, чтобы поместить эти for операторы в том же порядке, как они вошли бы регулярный вложенный for операторы.
Таким образом, это
for inner_list in outer_list:
for item in inner_list:
...
соответствует
[... for inner_list in outer_list for item in inner_list]
, Таким образом, Вы хотите
[image for menuitem in list_of_menuitems for image in menuitem]
@S.Lott: Вы вдохновили меня писать timeit приложение.
я полагал, что это будет также варьироваться на основе количества разделов (количество итераторов в рамках контейнерного списка) - Ваш комментарий не упоминал, сколько разделов там имело эти тридцать объектов. Этот график сглаживает тысячу объектов в каждом выполнении с переменным количеством разделов. Объекты равномерно распределяются среди разделов.
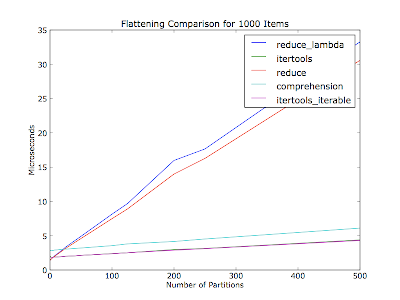
Код (Python 2.6):
#!/usr/bin/env python2.6
"""Usage: %prog item_count"""
from __future__ import print_function
import collections
import itertools
import operator
from timeit import Timer
import sys
import matplotlib.pyplot as pyplot
def itertools_flatten(iter_lst):
return list(itertools.chain(*iter_lst))
def itertools_iterable_flatten(iter_iter):
return list(itertools.chain.from_iterable(iter_iter))
def reduce_flatten(iter_lst):
return reduce(operator.add, map(list, iter_lst))
def reduce_lambda_flatten(iter_lst):
return reduce(operator.add, map(lambda x: list(x), [i for i in iter_lst]))
def comprehension_flatten(iter_lst):
return list(item for iter_ in iter_lst for item in iter_)
METHODS = ['itertools', 'itertools_iterable', 'reduce', 'reduce_lambda',
'comprehension']
def _time_test_assert(iter_lst):
"""Make sure all methods produce an equivalent value.
:raise AssertionError: On any non-equivalent value."""
callables = (globals()[method + '_flatten'] for method in METHODS)
results = [callable(iter_lst) for callable in callables]
if not all(result == results[0] for result in results[1:]):
raise AssertionError
def time_test(partition_count, item_count_per_partition, test_count=10000):
"""Run flatten methods on a list of :param:`partition_count` iterables.
Normalize results over :param:`test_count` runs.
:return: Mapping from method to (normalized) microseconds per pass.
"""
iter_lst = [[dict()] * item_count_per_partition] * partition_count
print('Partition count: ', partition_count)
print('Items per partition:', item_count_per_partition)
_time_test_assert(iter_lst)
test_str = 'flatten(%r)' % iter_lst
result_by_method = {}
for method in METHODS:
setup_str = 'from test import %s_flatten as flatten' % method
t = Timer(test_str, setup_str)
per_pass = test_count * t.timeit(number=test_count) / test_count
print('%20s: %.2f usec/pass' % (method, per_pass))
result_by_method[method] = per_pass
return result_by_method
if __name__ == '__main__':
if len(sys.argv) != 2:
raise ValueError('Need a number of items to flatten')
item_count = int(sys.argv[1])
partition_counts = []
pass_times_by_method = collections.defaultdict(list)
for partition_count in xrange(1, item_count):
if item_count % partition_count != 0:
continue
items_per_partition = item_count / partition_count
result_by_method = time_test(partition_count, items_per_partition)
partition_counts.append(partition_count)
for method, result in result_by_method.iteritems():
pass_times_by_method[method].append(result)
for method, pass_times in pass_times_by_method.iteritems():
pyplot.plot(partition_counts, pass_times, label=method)
pyplot.legend()
pyplot.title('Flattening Comparison for %d Items' % item_count)
pyplot.xlabel('Number of Partitions')
pyplot.ylabel('Microseconds')
pyplot.show()
Редактирование: Решительный для создания этого общественной Wiki.
Примечание: METHODS должен, вероятно, быть накоплен с декоратором, но я полагаю, что для людей было бы легче считать этот путь.