Короткий пример регулярного выражения преобразовывается в конечный автомат?
Этот код действителен. Разрешается выполнять преобразование между двумя типами указателей объектов и обратно при условии, что нет проблем с выравниванием, а преобразование в char * явно разрешает доступ к представлению объектов (т. Е. Считывает отдельные байты).
Раздел 6.3.2.3p7 стандарта C гласит:
Указатель на тип объекта может быть преобразован в указатель на другой тип объекта. Если результирующий указатель неправильно выровнен для ссылочного типа, поведение не определено. В противном случае при обратном преобразовании результат сравнивается равным исходному указателю. Когда указатель на объект преобразуется в указатель на тип символа, результат указывает на младший адресуемый байт объекта. Последовательные приращения результата, вплоть до размера объекта, дают указатели на оставшиеся байты объекта.
blockquote>Поскольку вы переходите от
int *кchar *, а затем обратно кint *, здесь нет строгих нарушений псевдонимов.
6 ответов
Несомненно, хотя Вам будут нужны более сложные примеры, чтобы действительно понять, как работают REs. Рассмотрите следующее РЕ:
^[A-Za-z][A-Za-z0-9_]*$
, который является типичным идентификатором (должен запуститься с альфы и может иметь любое количество алфавитно-цифровых и undescore символов после, включая ни один). Следующий псевдокод показывает, как это может быть сделано с конечным автоматом:
state = FIRSTCHAR
for char in all_chars_in(string):
if state == FIRSTCHAR:
if char is not in the set "A-Z" or "a-z":
error "Invalid first character"
state = SUBSEQUENTCHARS
next char
if state == SUBSEQUENTCHARS:
if char is not in the set "A-Z" or "a-z" or "0-9" or "_":
error "Invalid subsequent character"
state = SUBSEQUENTCHARS
next char
Теперь, поскольку я сказал, это - очень простой пример. Это не показывает, как сделать жадные/нежадные соответствия, отслеживание в обратном порядке, соответствуя в строке (вместо целой строки) и другие более тайные функции конечных автоматов, которые легко обрабатываются синтаксисом РЕ.
Вот почему REs так мощны. Фактический код конечного автомата, требуемый сделать, что может сделать РЕ остроты, обычно очень длинен и сложен.
лучшая вещь, которую Вы могли сделать, захватить копию некоторого lex/yacc (или эквивалентный) код для определенного простого языка и видеть код, который это генерирует. Это не симпатично (это не должно быть, так как это, как предполагается, не читается людьми, они, как предполагается, смотрят на код lex/yacc), но это может дать Вам лучшее представление относительно того, как они работают.
Я уверен, что у кого-то есть лучшие примеры, но Вы могли проверка это сообщение Phil Haack , который имеет пример регулярного выражения и конечного автомата, делающего то же самое (существует предыдущее сообщение еще с несколькими regex примерами там также, я думаю..)
Проверка "HenriFormatter" на той странице.
Сделайте свое собственное на лету!
http://osteele.com/tools/reanimator/???
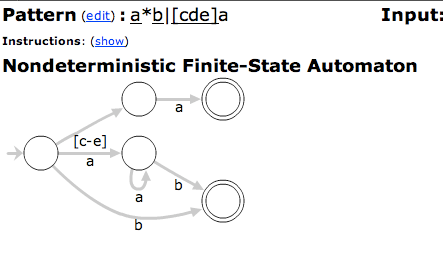
Это - действительно приятно соединенный инструмент, который визуализирует регулярные выражения как FSMs. Это не имеет поддержки части синтаксиса, который Вы найдете в реальных механизмах регулярного выражения, но конечно достаточно понять точно, что продолжается.
Довольно удобный способ помочь посмотреть на это для использования малоизвестного ре Python. Флаг DEBUG на любом шаблоне:
>>> re.compile(r'<([A-Z][A-Z0-9]*)\b[^>]*>(.*?)</\1>', re.DEBUG)
literal 60
subpattern 1
in
range (65, 90)
max_repeat 0 65535
in
range (65, 90)
range (48, 57)
at at_boundary
max_repeat 0 65535
not_literal 62
literal 62
subpattern 2
min_repeat 0 65535
any None
literal 60
literal 47
groupref 1
literal 62
числа после 'литерала' и 'диапазона' относятся к целочисленным значениям символов ASCII, которым они, как предполагается, соответствуют.
Вопрос, "Как я выбираю состояния и условия перехода?", или, "Как я реализую свой абстрактный автомат в Foo?"
, Как я выбираю состояния и условия перехода?
я обычно использую FSMs для довольно простых проблем и выбираю их интуитивно. В мой ответ на другой вопрос о регулярных выражениях , я просто посмотрел на проблему парсинга как на один из того, чтобы быть или Inside или outside пара тега и выписал переходы оттуда (с началом и конечным состоянием для содержания реализации в чистоте).
, Как я реализую свой абстрактный автомат в Foo?
, Если Ваш язык реализации поддерживает структуру как c switch оператор, то Вы включаете текущее состояние и обрабатываете вход для наблюдения, какое действие и/или переход также работают затем.
Без switch - как структуры, или если они являются несовершенными в некотором роде, Вы if ветвление стиля. Тьфу.
Записанный все в одном месте в c пример, который я связал, будет выглядеть примерно так:
token_t token;
state_t state=BEGIN_STATE;
do {
switch ( state.getValue() ) {
case BEGIN_STATE;
state=OUT_STATE;
break;
case OUT_STATE:
switch ( token.getValue() ) {
case CODE_TOKEN:
state = IN_STATE;
output(token.string());
break;
case NEWLINE_TOKEN;
output("<break>");
output(token.string());
break;
...
}
break;
...
}
} while (state != END_STATE);
, который довольно грязен, таким образом, я обычно срываю эти state случаи к отдельным функциям.
Я не знаю, какие научные газеты Вы уже прочитали, но действительно не настолько трудно понять, как реализовать конечный автомат. Существует некоторая интересная математика, но к идее на самом деле очень тривиально для понимания. Самый легкий способ понять FSM посредством ввода и вывода (на самом деле, это включает большую часть формального определения, которое я не опишу здесь). "Состояние" по существу просто описывает ряд входа и выводов, которые произошли и могут произойти от определенного момента.
Конечные автоматы является самым легким понять с помощью схем. Например:
сопроводительный текст http://img6.imageshack.us/img6/7571/mathfinitestatemachinedco3.gif
{kind=link}
, который Все это говорит, - то, что, если Вы начинаете в некотором состоянии q0 (тот с Начальным символом рядом с ним) можно перейти к другим состояниям. Каждое состояние является кругом. Каждая стрелка представляет ввод или вывод (в зависимости от того, как Вы смотрите на нее). Другой способ думать о конечном автомате с точки зрения "допустимого" или "приемлемого" входа. Существуют определенные выходные строки, которые НЕ являются возможными определенными конечными автоматами; это позволило бы Вам "соответствовать" выражениям.
Теперь предполагают, что Вы запускаете в q0. Теперь при вводе 0, Вы пойдете для утверждения q1. Однако при вводе 1, Вы пойдете для утверждения q2. Вы видите это символами выше стрелок ввода/вывода.
Скажем, Вы запускаете в q0 и получаете этот вход
0, 1, 0, 1, 1, 1
Это означает прохождение через состояний (никакой вход для q0, Вы только запускаете там):
q0-> q1-> q0-> q1-> q0-> q2-> q3-> Трассировка q3
изображение с Вашим пальцем, если это не имеет смысла. Заметьте, что q3 возвращается к себе для обоих исходных данных 0 и 1.
Другой способ сказать все это, "Если Вы находитесь в состоянии q0, и Вы видите, что 0 переходит к q1, но если Вы видите, что 1 переходит к q2". При создании этих условий для каждого состояния, Вы почти сделаны, определив Ваш конечный автомат. Все, что необходимо сделать, имеют переменную состояния и затем способ накачать вход в, и это в основном, что там.
хорошо, итак, почему это важное относительно оператора Joel? Ну, создание "ОДНОГО РЕГУЛЯРНОГО ВЫРАЖЕНИЯ TRUE ДЛЯ УПРАВЛЕНИЯ ИХ ВСЕХ" может быть очень трудным и также трудным поддержать, изменяют или даже чтобы другие возвратились и поняли. Кроме того, в некоторых случаях это более эффективно.
, Конечно, конечные автоматы имеют много другого использования. Надежда это помогает некоторым маленьким способом. Отметьте, я не потрудился входить в теорию, но существуют некоторые интересные доказательства относительно FSMs.