Эффективное сравнение 100 000 векторов
В случае, если кто-то сталкивается с проблемой использования уязвимой версии OpenSSL (< 1.0.2f/1.0.1r) в одной из нативных библиотек, я добавлю еще несколько деталей и инструкций.
Предварительные условия: Android NDK необходимо сначала настроить.
- Прежде всего, загрузите
OpenSSLсовместимую версию (> 1.0.2f/1.0.1r). -
Скачать два скрипта из по этой ссылке . В случае, если кому-то интересно, что они делают (и вам следует - это криптографическая библиотека !!!): они создают библиотеку
OpenSSLдля каждой архитектуры процессора Android ABI (armeabi,x86,mipsи т. Д.). ..) -
Изменить строку setenv-android-mod.sh ->
18с помощью версии ndk -
Изменить setenv-android- mod.sh -> line
40с версией Android API -
Измените build-all-arch.sh -> line
7, указав имя папки библиотекиOpenSSL(в моем случае это былоopenssl-1.0.1t) -
После успешной сборки, внутри папки
distбудут присутствовать библиотеки
добавьте openSSL для проецирования в виде готовых статических библиотек, создайте: папку
-
opensslв каталогеjni, содержащемlib/(который содержит файлы.aдля поддерживаемых архитектур), -
include/, который имеет необходимые элементы (вы можете найти, что в загруженной версии openssl учтите, что некоторые из заголовочных файлов являются символическими ссылками) -
Измените
Android.mkвнутри папкиjni, добавив следующее:include $(CLEAR_VARS) LOCAL_MODULE := libssl LOCAL_SRC_FILES := lib/$(TARGET_ARCH_ABI)/libssl.a include $(PREBUILT_STATIC_LIBRARY) include $(CLEAR_VARS) LOCAL_MODULE := libcrypto LOCAL_SRC_FILES := lib/$(TARGET_ARCH_ABI)/libcrypto.a include $(PREBUILT_STATIC_LIBRARY)
Затем, чтобы использовать библиотеку в другом jni добавьте в файл Android.mk следующее:
LOCAL_C_INCLUDES := $(LOCAL_PATH)/../openssl/include
LOCAL_STATIC_LIBRARIES := libssl libcrypto
10 ответов
Что делать, если вы используете Integrated Security = SSPI?
Если вы не хотите использовать вход в Windows, я считаю, что другой ответ об удалении параметра Integrated Security верен.
Известно, что m имеет встроенную поддержку kd-tree , поэтому вы можете попробовать реализовать следующее решение в MySQL , если вы ищете ограниченное количество ближайших записей:
- Сохраните проекции векторов на каждое из возможных
2-мерных пространств (занимаетn * (n - 1) / 2столбцов). - Индексируйте каждый из этих столбцов с помощью
SPATIALindex - Выберите квадрат
MBRзаданной области в любой проекции. Произведение этихMBRдаст вам гиперкуб ограниченного гиперобъема, который будет содержать все векторы с расстоянием не больше заданного. - Найти все проекции во всей
MBR.используетMBRContains
Вам все равно придется выполнять сортировку в пределах этого ограниченного диапазона значений.
Например,
Чтобы что-то отсортировать, вам нужен ключ сортировки для каждого элемента. Таким образом, вам потребуется обработать каждую запись хотя бы один раз, чтобы вычислить ключ.
Вы об этом думаете?
======= Комментарий перемещен сюда:
Учитывая описание, вы не можете избежать просмотра всех записей, чтобы вычислить свой коэффициент сходства. Если вы укажете базе данных использовать коэффициент подобия в предложении «порядок по», вы можете позволить ей делать всю тяжелую работу. Вы знакомы с SQL?
Таким образом, следующая информация может быть кэширована:
- Норма выбранного вектора
- Скалярное произведение AB, повторно используя его как для числителя, так и для знаменателя в данном Расчет T (A, B).
Если вам нужны только N ближайших векторов или если вы выполняете один и тот же процесс сортировки несколько раз, могут быть доступны дополнительные приемы. (Наблюдения вроде T (A, B) = T (B, A), кэширование векторных норм для всех векторов и, возможно, своего рода пороговая / пространственная сортировка).
Короче говоря, нет, вероятно, нет никакого способа избежать просмотра всех записей в базе данных. Одно уточнение по этому поводу; если у вас есть значительное количество повторяющихся векторов, вы можете избежать повторной обработки точных повторов.
ExtJS
Editable Grid: http: / Сетка редактора строк: http://extjs.com/deploy/ext-3.0-rc2/examples/ grid / row-editor.html
Я лично еще не использовал версии 3.0x, но 2.0 - это довольно круто. Фреймворк Ext требует некоторого обучения, но он делает практически все: проверку, ограничение ввода, привязку данных и т. Д.
есть несколько способов избежать обхода всей базы данных во время выполнения. В фоновом режиме вы можете начать предварительное вычисление попарных расстояний между векторами. Выполнение этого для всей базы данных является огромным вычислением, но его не нужно заканчивать, чтобы оно было полезным (т.е. начать вычисление расстояний до 100 случайных векторов для каждого вектора или около того. Сохраните результаты в базе данных).Затем триангулировать. если расстояние d между вашим целевым вектором v и некоторым вектором v 'велико, то расстояние между v и всеми другими v' ', близкими к v', тоже будет большим (-искренним), поэтому нет необходимости сравнивать их больше (хотя вам придется самостоятельно найти приемлемые определения термина "большой"). Вы можете поэкспериментировать с повторением процесса и для отброшенных векторов v '', и проверьте, сколько вычислений во время выполнения вы можете избежать, прежде чем точность начнет падать. (составьте тестовый набор «правильных» результатов для сравнений)
удачи.
sds
Новый ответ
Сколько предварительной обработки вы можете сделать? Можете ли вы заранее построить «окрестности» и отметить, в каком районе находится каждый вектор в базе данных? Это могло бы позволить вам исключить из рассмотрения многие векторы.
Старый ответ ниже, в котором предполагалось, что 60 было величиной всех векторов, а не размерностью.
Поскольку все векторы имеют одинаковую длину (60), я думаю, вы: Вы слишком много занимаетесь математикой. Разве вы не можете просто произвести скалярное произведение выбранного против каждого кандидата?
В 3D: 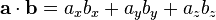
Три умножения. В 2D это всего лишь два умножения.
Или это нарушает ваше представление о подобии? Для меня наиболее похожими векторами являются те, между которыми наименьшее угловое расстояние.
А, нет?
Вам нужно всего лишь сделать все 99,999 против выбранной вами (а не всех n (n-1) / 2 возможных пар), конечно, но это как минимум.
] Глядя на ваш ответ на ответ nsanders , становится ясно, что вы уже освоили эту часть. Но я подумал об особом случае, когда вычисление полного набора сравнений может оказаться выигрышным. Если:
- список поступает медленно (скажем, вы получаете их из какой-то системы сбора данных с фиксированной низкой скоростью)
- , вы не знаете до конца, какую из них вы хотите сравнить с
- , у вас есть много места для хранения
- вам нужен быстрый ответ, когда вы все же выбираете один (и наивный подход - это не t достаточно быстро)
- Поиск выполняется быстрее, чем вычисление
, тогда вы можете предварительно вычислить по мере поступления данных и просто искать результаты для каждой пары во время сортировки. Это также может быть эффективным, если вы в конечном итоге будете выполнять много разных операций ...
Не просматривая все записи? Кажется, это невозможно. Единственное, что вы можете сделать, - это выполнить вычисления во время вставки (помня, что эквивалентность http://tex.nigma.be/T%2528A%252CB%2529%253DT%2528B%252CA%2529.png ] :П ).
{kind=link}
Это позволяет избежать вашего запроса на проверку списка по сравнению со всеми другими списками во время выполнения (но это может значительно увеличить пространство, необходимое для базы данных)
Компилятор должен уметь распознавать, что BigFoo не может быть преобразован в IEnumerable , но это не так. т. Он просто видит, что это IEnumerable , и чувствует, что это потенциальный кандидат на перегрузку (даже несмотря на то, что ограничение, которое вы определили, заставляет T быть IFoo и int нельзя преобразовать в IFoo ). Хотя это неудобно, но это не так уж и важно. Просто приведите bigFoo к IFoo , и компилятор будет доволен:
fooContainer.Add((IFoo)bigFoo);
В качестве альтернативы вы можете сделать свою общую перегрузку Add uglier:
public void Add<T, U>(U group)
where T : IFoo
where U : IEnumerable<T>
{
}
В любом случае у вас будет больше ввода, второе решение устранит необходимость для вызова Добавить ,
Обратите внимание, что ваша функция сравнения T () теперь имеет члены величин, которые становятся постоянными, и формулу можно упростить до нахождения наибольшего скалярного произведения между вашим тестовым вектором и значениями в базе данных.
Теперь подумайте о новой функции D = расстояние между двумя точками в пространстве 60D. Это классическое расстояние L2 , возьмите разность каждого компонента, возведите каждую в квадрат, сложите все квадраты и извлеките квадратный корень из суммы. D (A, B) = sqrt ((AB) ^ 2), где A и B - каждый по 60 размерных векторов.
Однако это можно расширить до D (A, B) = sqrt (A * A -2 * точка (A, B) + B * B). Значит, А и В - единичная величина. А функция D монотонна, поэтому она не изменит порядок сортировки, если мы удалим sqrt () и посмотрим на квадраты расстояний. Остается только -2 * точка (A, B). Таким образом, расстояние минимизации в точности эквивалентно максимизации скалярного произведения.
Таким образом, исходная метрика классификации T () может быть упрощена до нахождения наивысшего скалярного произведения между норнализованными векторами. И это сравнение показано эквивалентным нахождению ближайших точек к точке выборки в пространстве 60D.
Итак, теперь все, что вам нужно сделать, это решить эквивалентную задачу «с учетом нормализованной точки в 60D. пробел, перечислите 20 точек в базе данных нормализованных векторов выборок, которые являются ближайшими к нему. "
Эта проблема хорошо изучена ... это K ближайших соседей. Есть много алгоритмов решения этой проблемы. Наиболее распространены классические деревья KD. .
Но есть проблема. Деревья KD имеют поведение O (e ^ D) ... высокая размерность быстро становится болезненной. И 60 измерений определенно относятся к этой крайне болезненной категории. Даже не пытайтесь.
Однако есть несколько альтернативных общих методов для ближайшего соседа с высоким D. Эта статья дает ясный метод.
Но на практике есть отличное решение, включающее еще одно преобразование. Если у вас есть метрическое пространство (которое у вас есть, или вы бы не использовали сравнение Танимото), вы можете уменьшить размерность проблемы с помощью поворота на 60 измерений. Это звучит сложно и пугающе, но это очень распространено ... это форма разложения по сингулярным значениям или разложения по собственным значениям. В статистике он известен как Анализ главных компонентов.
В основном он использует простое линейное вычисление, чтобы определить, в каких направлениях ваша база данных действительно простирается. Вы можете свернуть 60 измерений до меньшего числа, возможно, до 3 или 4, и при этом иметь возможность точно определять ближайших соседей. Для этого существует множество программных библиотек на любом языке, см., Например, здесь .
Наконец, вы сделаете классический K ближайших соседей, вероятно, только в 3-10 измерениях .. вы можете экспериментировать для лучшего поведения. Для этого есть замечательная библиотека под названием Ranger , но вы можете использовать и другие библиотеки. Большое побочное преимущество заключается в том, что вам даже больше не нужно хранить все 60 компонентов ваших выборочных данных!
Тяжелый вопрос заключается в том, действительно ли ваши данные могут быть свернуты до более низких размеров, не влияя на точность результатов. На практике разложение PCA может сказать вам максимальную остаточную ошибку для любого выбранного вами предела D, поэтому вы можете быть уверены, что это работает. Поскольку точки сравнения основаны на метрике расстояния, весьма вероятно, что они сильно коррелированы, в отличие от значений, скажем, хэш-таблицы.
Итак, резюме вышеизложенного:
- Нормализуйте ваши векторы, преобразовав вашу проблему в проблему K-ближайшего соседа в 60 измерениях.
- Используйте анализ основных компонентов, чтобы уменьшить размерность до управляемой предел, скажем, 5 измерений
- Используйте алгоритм ближайшего соседа K, такой как библиотека дерева KD Ranger, чтобы найти близлежащие образцы.
Другой подход к этому - проблема всех пар с заданным порогом для некоторой функции подобия. Посмотрите статью и код Баярдо здесь http://code.google.com/p/google-all-pairs-similarity-search/
Я не знаю, соответствует ли ваша функция подобия подходу, но если так, то это еще один прием, на который стоит обратить внимание. В любом случае также потребуются нормализованные и отсортированные векторы.