Какие функции профилировщик C#/.NET должен иметь?
if not a:
print("List is empty")
Используя неявные булевы из пустых list вполне pythonic.
14 ответов
Мои требования:
- Собирать статистику без воздействия на приложение - например, не заполнять память, разрешать сбор данных из рассматриваемых приложений
- Возможность простого и простого задания измерений повторяемость (управляемость данными)
- Автоматизация, так что я могу повторять измерения без наведения и щелчка и без пользовательского интерфейса
- Позволяет нам понять проблемы, связанные с WPF и другими декларативными технологиями, такими как DLR или WF
- Без установки - нет gac, msi и т. д., даже лучше, если их можно запустить по сети
- Поддержка 64 бит с самого начала
- Не пытайтесь знать весь анализ, который можно было бы сделать - поощряйте экосистему. Если исходную статистику можно будет проанализировать с помощью других инструментов, тем лучше.
- Пользовательский интерфейс, если он есть, должен быть хорошим, но важна его статистика. Так что не тратьте на это время, получите хорошее профилирование ядра.
- Поддерживать профилирование приложений, которые не являются простыми исполняемыми файлами, такими как просто сервисы и веб-приложения.
хотелось бы:
- Подумать о поддержке кросс-приложений - большим приложениям часто необходимо понимать поведение приложений во многих исполняемых файлах. Если ваш профилировщик позволяет легко коррелировать эти данные, тем лучше.
Пара вещей, которые я действительно хотел бы увидеть:
Сбор данных:
- Возможность отслеживания контекста через новый поток. То есть, когда происходит вызов либо new Thread (), либо ThreadPool.Queue ... (), подсчитывайте работу, выполненную другим потоком, как если бы она происходила внутри вызывающей функции, даже если они выполняются в разных потоках, и метод вызова на самом деле не блокирует. В конечном итоге это позволило бы идентифицировать код, который выполняет много работы в общем методе, реализующем асинхронный шаблон. Это действительно могло бы быть здорово!
- Отслеживание распределения внутри методов. Есть шанс, что профилировщик памяти .Net уже делает это, но определение того, какие методы выполняют много распределений, может быть бесценным. Даже если другие инструменты могут это сделать, всегда здорово иметь все в одном инструменте.
- Агрегирование, способное обнаруживать «всплески» использования и анализировать только их. Это может быть удобно при анализе фонового процесса, который ведет себя неожиданно и редко.
Конец пользовательского интерфейса:
- Возможность сравнивать два запуска и выделять основные различия между ними.
- Навигация по дереву вызовов и расширение горячих путей ( VS-style) тоже подойдет.
Я хотел бы по крайней мере некоторую совместимость с ASP.NET, хотя я понимаю, что на самом деле довольно сложно заставить это работать.
Построчно в Shark так хорошо, что я бы тоже хотел, чтобы это было. NET.
Выбор визуализаторов - это хорошо - я »
Моим предпочтительным профилировщиком был "DevPartner Performance Analysis Community Edition" ( http://researchlibrary.theserverside.net/detail/RES/1165507815_474.html?psrc=MPR ) , к сожалению, он больше не доступен.
Что выделяло его среди конкурентов, так это графический анализ, который показал поле для текущего выбранного метода и исходящие соединители для вызываемых методов, показывающие процент времени, затраченного на каждый из них. Также разъемы для входящих звонков. Конечно, у вызывающих и вызываемых методов было то же самое, и вы могли расширять их по мере необходимости. Таким образом, вы могли бы свободно перемещаться по стеку вызовов, видеть стек настолько глубоко, насколько захотите, и заниматься горячим путем в вашем фрагменте.
Вторым требованием будет «простота использования», то есть он должен работать со всеми соответствующие типы приложений, Windows exe, веб-приложение, служба Windows, служба WCF, (Silverlight?), .... И не только с небольшими примерами приложений, но и с нетривиальными приложениями корпоративного размера.
Было бы неплохо, если бы меры профилирования, связанные с .NET, из Perfmon были интегрированы, чтобы вы избегали «двойного» мониторинга с помощью perfmon и вашего приложения. Это особенно полезно для всех элементов, связанных с памятью.
Я добавлю сюда еще одно, что было бы действительно мило. Создайте простую сборку с доступной функцией Mark (string) , где если приложение вызвало этот метод, то в результатах вы можете выбрать, чтобы увидеть результаты прямо оттуда в ( конец | какой-то другой указанный знак). Другая возможность - BeginSequence и EndSequence или что-то в этом роде. Двойной плюс, если вы можете указать, применяется ли метка только к текущему потоку или ко всем потокам.
Если бы он делал то же самое, что и JetBrains dotTrace , я был бы очень счастлив.
Загрузите версию Visual Studio 2010 Beta 1 для Team Suite (бесплатно в течение 6 месяцев или около того?) И профилируйте приложение C #.
Поверьте мне. :)
Редактировать: Построчный режим помог мне выделить оператора, который вызывал проблемы с производительностью. Я мог бы найти его без построчного выделения, но когда вы можете прокручивать и видеть горячие линии с его помощью, вы можете это очень легко исправить.
О, и если вам нужна обратная связь / помощь, свяжитесь со мной отдельно.
Обзор: выберите любой раздел диаграммы ЦП для фильтрации.
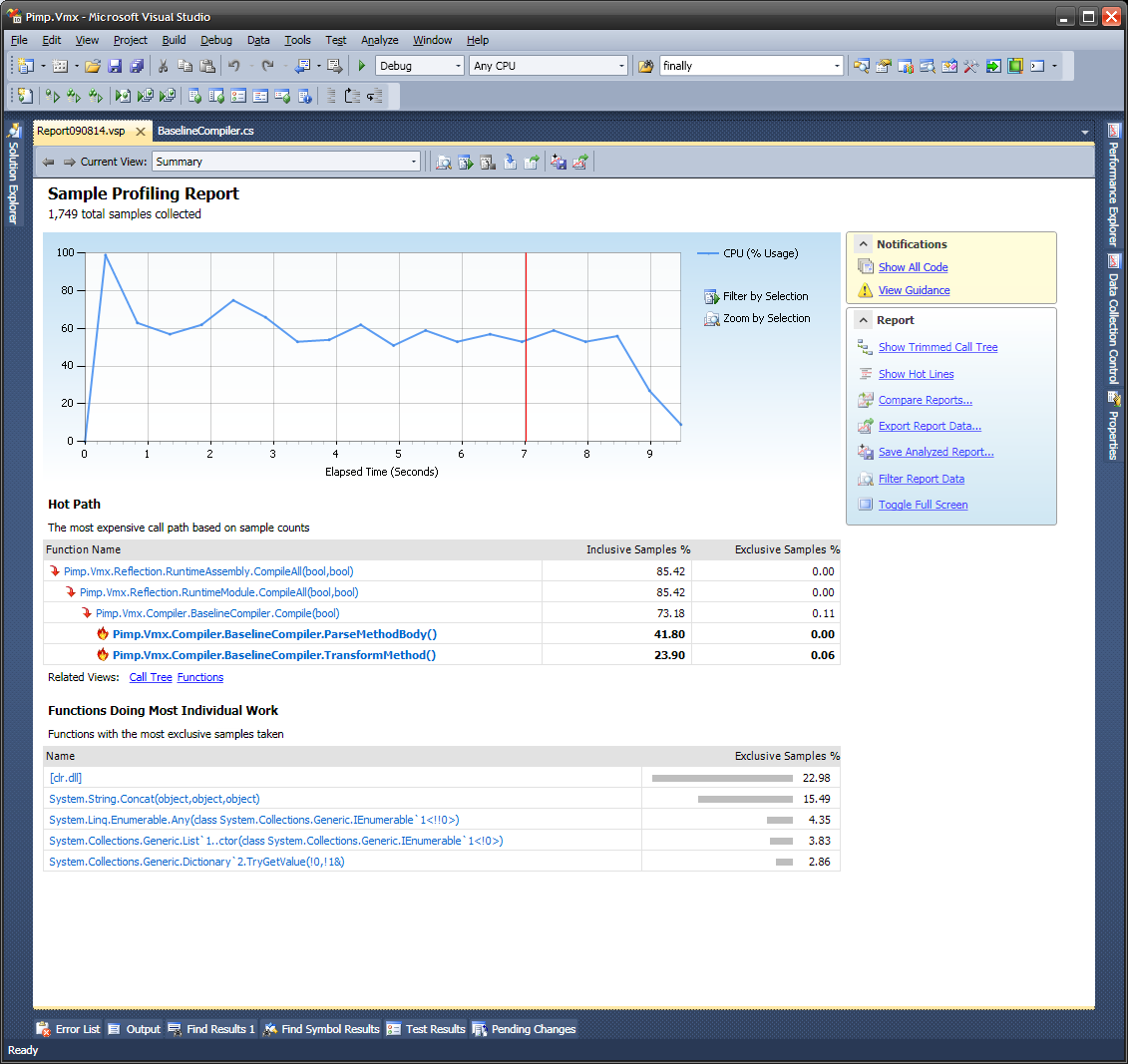
(источник: 280z28.org )
{kind=link}
Мне нравится построчное на полях:
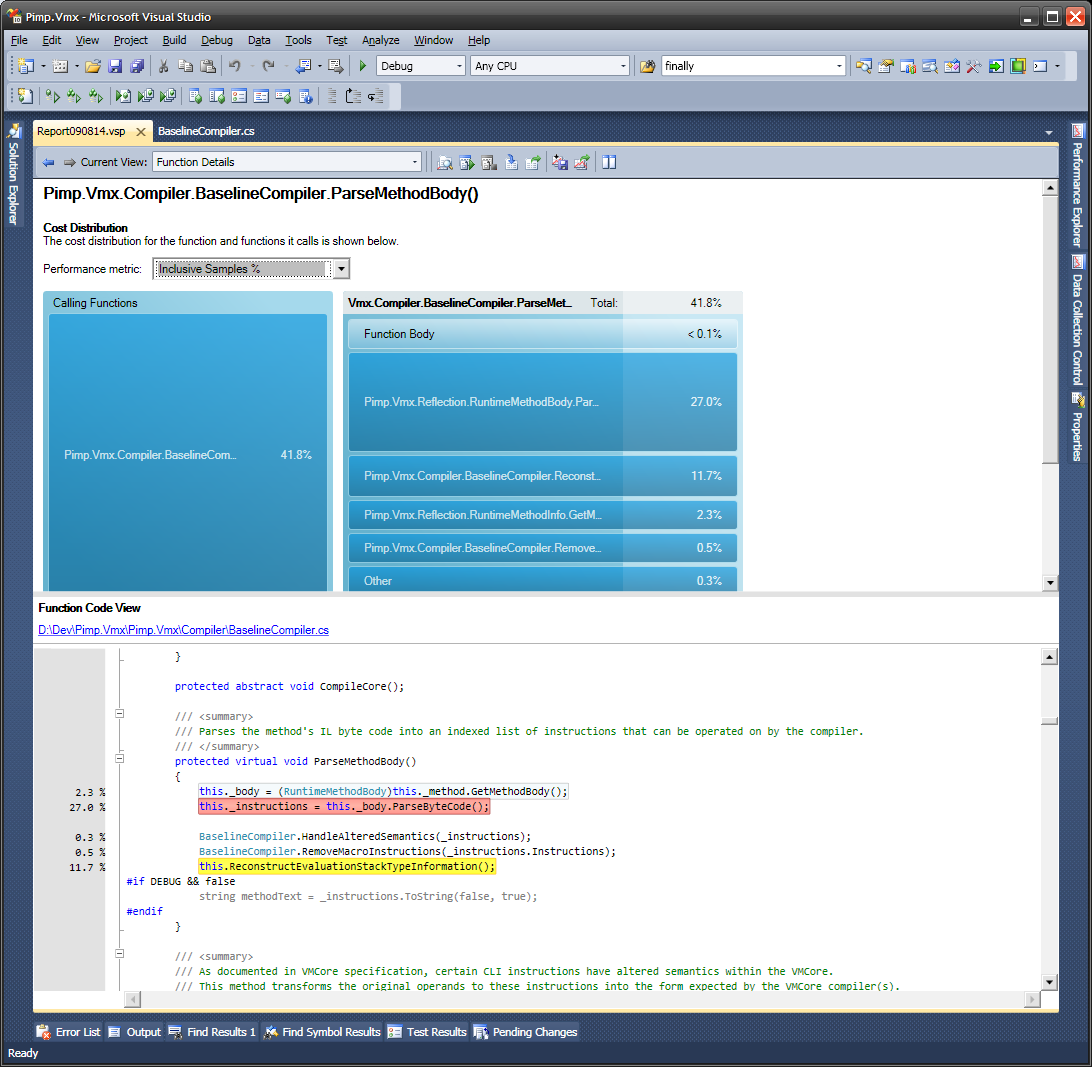
(источник : 280z28.org )
{kind=link}
Мой список пожеланий:
- Действительно проста в использовании - простой (но мощный) графический интерфейс
- Впечатляющая производительность - возможность профилировать приложения, которые очень часто используются.
- Поддержка X64 и X32
- Понимает SQL , может предоставить мне трассировку стека и продолжительность всех моих вызовов SQL в сочетании с SQL.
- Легко профилировать. , не нужно проходить сложный процесс перекомпиляции приложения.
- Простое профилирование сервисов, веб-сайтов и процессов, запускаемых как побочные эффекты
- «Рабочий режим», который позволяет вам собирать ключевую статистику из производственной системы.
- «Автоматический поиск узких мест»: запустить в производственном приложении и с помощью эвристики определить, какие методы являются медленными.
- Анализ каждого потока, скажите мне, какие потоки выполняют всю работу и где.
- Профиль с различной степенью детализации, позволяют создать "дешевый" профиль, который собирает только ключевую информацию и углубляется с детальным профилированием.
- Счетчик исключений, позволяет мне отслеживать все исключения, которые возникают в моем приложении (основная статистика и подробная информация).
- Профилирование каждого потока - позволяет мне профилировать отдельный поток в приложении
Существует EQATEC Profiler , бесплатный профилировщик .Net, который я собирался использовать. .
Одна вещь, которую я хотел бы видеть, - это совместимость с Mono. Я начал заниматься Mono, и было бы здорово иметь профилировщик .Net и Mono!
Что бы я хотел от профилировщика:
- Должен работать на 32 и 64 битах
- Должны быть компоненты для всех уровней (клиент, сервер приложений, база данных) и какой-то способ корреляции между ними. Например, было бы неплохо увидеть, как изменения, внесенные в любой из уровней, влияют на другие уровни. Это может помочь решить, на каком уровне реализовать определенные функции.
- Интерфейс командной строки для использования с автоматическими сценариями (сервер сборки, стресс-тестирование и т. Д.)
- Должен иметь упрощенный режим выборки и более точный инструментальный режим. Второй должен как можно меньше влиять на показатели выполнения.
- Графический интерфейс для простоты использования, который должен генерировать необходимые файлы конфигурации для использования режима командной строки em
- Генерировать результаты в стандартном формате (если такой существует), чтобы я мог использовать результаты с другими инструментами
- Должен также генерировать или экспортировать результаты в формат Visual Studio (* .vsp)
- Сравнить между двумя или более файлами результатов, чтобы увидеть эволюцию или регресс кодовой базы.
- Соберите и сопоставьте данные целевого приложения с данными PerfMon других процессов, запущенных на каждой целевой машине, для определения одновременного использования ресурсов (память, процессор, диск и сетевой ввод-вывод)
- Определите пороговые значения, для которых следует активировать какой-либо механизм предупреждения. Примером такого может быть электронное письмо кому-то, если конкретный сценарий занимает больше времени, чем указано.
- Возможность подключения и отключения от запущенного процесса для сбора данных выборки без вмешательства в работу целевого приложения. Требуется для использования на производственных сайтах.
Одна из вещей, которую я упускаю почти во всех профилях, - это управляемый API для выполнения автоматического профилирования и автоматических тестов.
Я могу представить, что вы думаете, черт возьми ... автоматизировать профилирование?
Ответ заключается в том, что у некоторых наших клиентов есть требования относительно скорости, использования памяти и т. д. Поэтому для каждого нового выпуска мы хотели бы проводить тестирование упомянутого материала перед его отправкой.
Phsr уже упоминал EQATEC Profiler .
Мне нравится, что он имеет одну особенность, даже не читая никакой документации и не обращая внимания на то, что я делаю, мне удалось успешно профилировать приложение от начала до конца. Юзабилити - замечательная вещь. Пожалуйста, будьте осторожны с тем, как вы добавляете все эти причудливые опции ... не убивайте удобство использования в процессе.
Несколько лет назад я построил профилировщик и описал его на SO в ответ на другой вопрос, который я не могу найти прямо сейчас, о том, как построить профилировщик.
Он основан на по крайней мере частично автоматизируя технику, которую я использовал на протяжении десятилетий, пример которой приведен здесь . Он основан на выборке стека, и ключ кроется в том, как эта информация представлена, и в мыслительном процессе, через который проходит пользователь.
Общие представления о настройке производительности, которым учат в школе (профессорами, мало знакомыми с реальное программное обеспечение) и, продолжая через феномен 50 000 программистов, которые не могут ошибаться, я предлагаю задать вопросы и поставить на более прочную основу. Я далеко не одинок в таких чувствах, как вы могли понять, путешествуя по SO.
Я думаю, что технология профилировщика постепенно развивается (на мой взгляд, в лучшую сторону) в сторону выборки стека и способов исследования результатов. Вот идеи, на которые я полагаюсь (которые могут вас немного раздражать):
Выявление проблем с производительностью, чтобы их можно было исправить, и измерение производительности - две совершенно разные задачи. Это средства и цели, и их не следует путать.
Чтобы выявить проблемы с производительностью, необходимо выяснить, на какие действия приходится большое количество времени, затрачиваемого на настенные часы и , которые можно заменить с чем-то более быстрым.
Хорошая вещь в таких действиях заключается в том, что сам факт того, что они занимают время, подвергает их случайным выборкам состояния программы.
Не нужно много выборок, если они берутся во время интервал, который вам небезразличен. Т.е. там ' s Нет смысла брать пробы в ожидании ввода данных пользователем. С этой целью в моем профилировщике я позволяю пользователю запускать образцы с помощью ключей.
Причина, по которой вам не нужно много образцов, заключается в следующем. Любая заданная проблема производительности стоит некоторую долю X времени настенных часов в интересующем интервале. Случайная выборка в этом интервале имеет вероятность X «поймать ее во время действия», поэтому, если будет взято N выборок, ожидаемое количество выборок, улавливающих ее во время действия, будет NX. Стандартное отклонение этого количества выборок равно sqrt (NX (1-X)). Например, если N = 20 и X = 20%, можно ожидать, что примерно от 2 до 6 образцов покажут проблему. Это дает вам неточную оценку проблемы, но говорит о том, что ее стоит исправить, и дает очень точное местонахождение без какой-либо дополнительной детективной работы.
Проблемы обычно проявляются в виде дополнительных функций, вызовы процедур или методов, чем это необходимо, особенно когда программное обеспечение становится большим, с большим количеством уровней абстракции и, следовательно, с большим количеством слоев стека. Первое, что я ищу, - это сайты вызовов (не функции, а операторы вызова или инструкции), которые появляются в нескольких образцах стека. Чем больше образцов стека они появляются, тем дороже они стоят. Второе, что я ищу, это "можно ли их заменить?" Если их абсолютно невозможно заменить чем-то более быстрым, тогда они просто необходимы, и мне нужно искать в другом месте. Но часто их можно заменить, и я получаю хорошее ускорение. Поэтому я внимательно смотрю на конкретные образцы стека, а не объединяю их в измерения.
Рекурсия не является проблемой, потому что принцип, согласно которому стоимость инструкции - это процент времени, в течение которого она находится в стеке, одинаков, даже если он называет себя.
Я делаю это не один раз, а последовательно. Каждая исправляемая мною проблема сокращает время работы программы. Это означает, что другие проблемы становятся все более частыми, что упрощает их поиск. Этот эффект усугубляется, так что часто возможны резкие кумулятивные улучшения производительности.
Я мог бы продолжить, но желаю вам удачи, потому что я думаю, что есть потребность в лучших инструментах профилирования, и у вас есть хорошие шансы.