Как эффективное памятью неразрушающее управление наборами достигнуто в функциональном программировании?
Я пытаюсь выяснить, как неразрушающее управление большим количеством реализовано в функциональном программировании, т.е. как возможно изменить или удалить единственные элементы, не имея необходимость создавать абсолютно новый набор, где все элементы, даже неизмененные, будут дублированы в памяти. (Даже если бы исходный набор был бы собран "мусор", я ожидал бы, что объем потребляемой памяти и общая производительность такого набора будут ужасны.)
Это - то, как далеко я имею до сих пор:
Используя F#, я придумал функцию insert это разделяет список на две части и представляет новый промежуток элемента, по-видимому не клонируя все неизменные элементы:
// return a list without its first n elements:
// (helper function)
let rec skip list n =
if n = 0 then
list
else
match list with
| [] -> []
| x::xs -> skip xs (n-1)
// return only the first n elements of a list:
// (helper function)
let rec take list n =
if n = 0 then
[]
else
match list with
| [] -> []
| x::xs -> x::(take xs (n-1))
// insert a value into a list at the specified zero-based position:
let insert list position value =
(take list position) @ [value] @ (skip list position)
Я тогда проверил, "переработаны" ли объекты из исходного списка в новых списках при помощи.NET Object.ReferenceEquals:
open System
let (===) x y =
Object.ReferenceEquals(x, y)
let x = Some(42)
let L = [Some(0); x; Some(43)]
let M = Some(1) |> insert L 1
Следующие три выражения все оценивают к true, указание, что значение, упомянутое x снова используется оба в списках L и M, т.е. это там - только 1 копия этого значения в памяти:
L.[1] === x
M.[2] === x
L.[1] === M.[2]
Мой вопрос:
Языки функционального программирования обычно снова используют значения вместо того, чтобы клонировать их к новой ячейке памяти, или я был просто удачлив с поведением F#? Принятие первого, это, как довольно эффективное памятью редактирование наборов может быть реализовано в функциональном программировании?
(Btw.: Я знаю о книге Chris Okasaki Чисто функциональные структуры данных, но еще не имел времени для чтения ее полностью.)
5 ответов
Я пытаюсь понять как неразрушающая манипуляция крупными коллекции реализованы в функциональное программирование, т.е. как это можно изменить или удалить один элементы без необходимости создания совершенно новая коллекция, где все элементы, даже немодифицированные, будет дублироваться в памяти.
Эта страница содержит несколько описаний и реализаций структур данных в F#. Большинство из них исходит от Окасаки Purely Functional Data Structures, хотя AVL-дерево - это моя собственная реализация, так как его не было в книге.
Теперь, раз уж Вы спросили о повторном использовании немодифицированных узлов, давайте возьмем простое двоичное дерево:
type 'a tree =
| Node of 'a tree * 'a * 'a tree
| Nil
let rec insert v = function
| Node(l, x, r) as node ->
if v < x then Node(insert v l, x, r) // reuses x and r
elif v > x then Node(l, x, insert v r) // reuses x and l
else node
| Nil -> Node(Nil, v, Nil)
Обратите внимание, что мы повторно используем некоторые из наших узлов. Допустим, мы начнем с этого дерева:
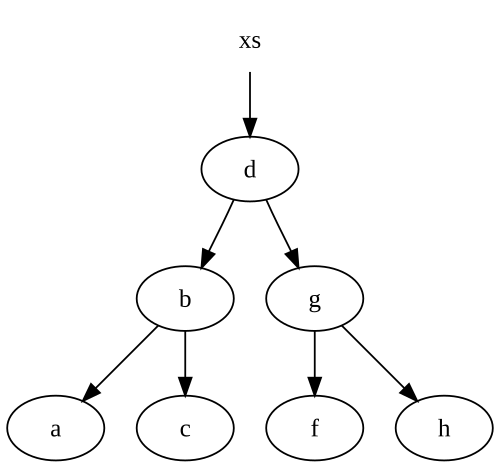
Когда мы вставляем e в это дерево, мы получаем совершенно новое дерево, при этом некоторые узлы указывают на наше исходное дерево:

Если у нас нет ссылки на дерево xs выше, то . NET будет собирать мусор без живых ссылок, а именно: d, g и f.
Обратите внимание, что мы изменили только узлы по пути нашего вставленного узла. Это довольно типично для большинства неизменяемых структур данных, включая списки. Таким образом, количество создаваемых нами узлов в точности равно количеству узлов, через которые нам нужно пройти, чтобы вставить их в нашу структуру данных.
Do functional programming languages как правило, значения повторного использования вместо клонирование их в новую ячейку памяти, или мне просто повезло с F#. Поведение? Если предположить, что первое как разумно эффективно с точки зрения памяти редактирование коллекций может быть Реализованные в функциональном программировании?
Да.
Списки, однако, не очень хорошие структуры данных, так как большинство нетривиальных операций над ними требуют времени O(n).
Сбалансированные двоичные деревья поддерживают вставки O(log n), что означает, что мы создаем копии O(log n) на каждой вставке. Так как log2(10^15) ~= 50, то накладные расходы очень малы для этих конкретных структур данных. Даже если вы будете хранить вокруг каждой копии каждого объекта после вставки/удаления, использование памяти будет увеличиваться со скоростью O(n log n) - очень разумно, на мой взгляд
.Вас могут заинтересовать стратегии сокращения выражений в функциональных языках программирования. Хорошей книгой на эту тему является The Implementation of Functional Programming Languages, автор Саймон Пейтон Джонс, один из создателей Haskell. Особенно стоит обратить внимание на следующую главу Graph Reduction of Lambda Expressions, поскольку в ней описывается совместное использование общих подвыражений. Надеюсь, это поможет, но боюсь, что это относится только к ленивым языкам.
. В то время как объекты, на которые делаются ссылки, одинаковы в Вашем коде,
Я верю, что место для хранения самих ссылок.
и структура списка
дублируется дублем .
В результате, в то время как объекты, на которые делаются ссылки, одинаковы,
и хвосты делятся между двумя списками,
"ячейки" для начальных порций дублируются.
Я не эксперт по функциональному программированию, но, может быть, с помощью какого-нибудь дерева ты сможешь достичь дублирование только элементов журнала (n), так как вам придется воссоздавать только путь от корня. к вставленному элементу.
php не предлагает встроенную функцию для этого афайка, но вот что я использую
function uncamelize($camel,$splitter="_") {
$camel=preg_replace('/(?!^)[[:upper:]][[:lower:]]/', '$0', preg_replace('/(?!^)[[:upper:]]+/', $splitter.'$0', $camel));
return strtolower($camel);
}
разветвитель может быть указан в вызове функции, так что вы можете называть его так
$camelized="thisStringIsCamelized";
echo uncamelize($camelized,"_");
//echoes "this_string_is_camelized"
echo uncamelize($camelized,"-");
//echoes "this-string-is-camelized"
Это звучит для меня как ваш вопрос прежде всего о неизменяемых данных , а не функциональных языках per se . Данные действительно обязательно незыблемы в чисто функциональном коде (ср. ссылочная прозрачность ), но я не знаю ни одного нетонического языка, который везде обеспечивает абсолютную чистоту (хотя Хаскелл подходит ближе всего, если вам нравится такая вещь).
Грубо говоря, ссылочная прозрачность означает, что не существует никаких практических различий между переменной/выражением и значением, которое оно удерживает/оценивает. Поскольку часть неизменяемых данных (по определению) никогда не изменится, она может быть тривиально идентифицирована со своей ценностью и должна вести себя неотличимо от любых других данных с такой же ценностью.
Поэтому, принимая решение не проводить семантического различия между двумя частями данных с одинаковым значением, у нас нет причин когда-либо намеренно строить дублирующее значение. Так, в случаях очевидного равенства (например, добавление чего-либо в список, передача его в качестве аргумента функции, & c.) языки, где возможны гарантии неизменности, как правило, будут повторно использовать существующую ссылку, как вы говорите.
Также неизменные структуры данных обладают внутренней ссылочной прозрачностью своей структуры (хотя и не их содержимого). Предполагая, что все содержащиеся значения также являются неизменными, это означает, что части структуры могут быть безопасно использованы и в новых структурах. Например, хвостовая часть списка недостатков часто может использоваться повторно; в вашем коде я ожидал, что
(skip 1 L) === (skip 2 M)
... также будет правдой.
Однако повторное использование не всегда возможно; Например, невозможно повторно использовать начальную часть списка, удаленного функцией skip . По той же причине добавление чего-либо в конец списка недостатков является дорогостоящей операцией, так как она должна реконструировать целый новый список, подобно проблеме с конкатенацией последовательностей с нулевым окончанием.
В таких случаях наивные подходы быстро попадают в сферу ужасных показателей, которые вас беспокоили. Часто необходимо существенно переосмыслить фундаментальные алгоритмы и структуры данных, чтобы успешно адаптировать их к неизменяемым данным. Методы включают разделение структур на слоистые или иерархические части для выделения изменений, инвертирование частей структуры для предоставления дешевых обновлений частым измененным частым частям или даже хранение исходной структуры вместе с набором обновлений и объединение обновлений с оригиналом на лету только при обращении к данным.
Поскольку вы используете F # здесь, я предполагаю, что вы хотя бы немного знакомы с C #; неоценимый Эрик Липперт имеет множество постов на неизменяемых структурах данных в C #, которые, вероятно, просветят вас далеко за пределы того, что я мог бы предоставить.На протяжении нескольких постов он демонстрирует (достаточно эффективные) неизменяемые реализации стека, двоичного дерева и двойной очереди, среди прочих. Восхитительное чтение для любого программиста .NET!
-121--2130547-Как можно изменить или удалить отдельные элементы без создания совершенно новой коллекции, в которой все элементы, даже немодифицированные, будут дублироваться в памяти.
Это работает, потому что независимо от вида сбора указатели на элементы хранятся отдельно от самих элементов. (Исключение: некоторые компиляторы будут оптимизировать часть времени, но они знают, что они делают.) Так, например, можно иметь два списка, различающихся только в первом элементе и разделяющих хвосты:
let shared = ["two", "three", "four"]
let l = "one" :: shared
let l' = "1a" :: shared
Эти два списка имеют общую часть, а их первые элементы различаются. Менее очевидно, что каждый список также начинается с уникальной пары, часто называемой «недостатками камеры»:
Список
lначинается с пары, содержащей указатель на«один»и указатель на общий хвост.Список
l 'начинается с пары, содержащей указатель на«1a»и указатель на общий конец.
Если бы мы только объявили l и хотели изменить или удалить первый элемент , чтобы получить l ', мы бы сделали это:
let l' = match l with
| _ :: rest -> "1a" :: rest
| [] -> raise (Failure "cannot alter 1st elem of empty list")
Существует постоянная стоимость:
разбить
lна его голову и хвост, проверяя недостатки камеры.Выделите новую ячейку недостатков, указывающую на
«1a»и конец.
Новая ячейка недостатков становится значением списка l '.
Если вы делаете точечные изменения в середине большой коллекции, как правило, вы будете использовать своего рода сбалансированное дерево, которое использует логарифмическое время и пространство. Реже можно использовать более сложную структуру данных:
застежку-молнию Джерарда Хуэта можно определить практически для любой древовидной структуры данных и использовать для обхода и внесения точечных изменений при постоянной стоимости. Молнии легко понять.
Пальцевые деревья Патерсона и Хинзе предлагают очень сложные представления последовательностей, которые среди прочих трюков позволяют эффективно менять элементы в середине - но их трудно понять.
Это звучит мне, как ваш вопрос в первую очередь о неизменных данных , а не функциональные языки SE . Данные действительно обязательно неизменяются в чисто функциональном коде (см. реферантной прозрачности ), но я не знаю ни одному негружими языками, которые обеспечивают абсолютную чистоту везде (хотя Haskell приходит ближе всего, если вам нравится такой вещи).
Грубо говоря, реферативная прозрачность означает, что не существует никаких практических различий между переменной / выражением и значением, которое он содержит / оценивает. Поскольку часть неизменных данных будет (по определению) никогда не меняется, он может быть тривециально идентифицирован со своим значением и должен вести себя неразличимым от любых других данных с одинаковым значением.
Следовательно, избирая не нарисовать семантическое различие между двумя деталями с одинаковым значением, у нас нет причин, чтобы когда-либо намеренно построить дублирующее значение. Таким образом, в случаях очевидного равенства (например, добавляя что-то в список, передавая его в качестве функционального аргумента, &c.), Языки, где возможны гарантии неизменности, вообще повторно используют существующую ссылку, как вы говорите.
Аналогичным образом, неизменные структуры данных обладают внутренней референтной прозрачностью их структуры (хотя и не их содержимого). Предполагая, что все содержащиеся содержащиеся значения также неизменяются, это означает, что кусочки структуры могут быть безопасно повторно использованы в новых структурах. Например, хвост пов условиями часто можно повторно использовать; В вашем коде я ожидал, что:
(skip 1 L) === (skip 2 M)
... также будет правдой.
Повторное использование не всегда возможно, хотя; Начальная часть списка удалена вашим функцией Skip , например, не может быть повторно использовано. По той же причине, добавление чего-то до конца гобущего списка - это дорогостоящая операция, поскольку она должна реконструировать совершенно новый список, аналогичный проблему с объединяющимися пустяками строк.
В таких случаях наивные подходы быстро попадают в царство ужасных характеристик, о которых вы были обеспокоены. Часто необходимо существенно переосмыслить фундаментальные алгоритмы и структуры данных, чтобы успешно адаптироваться к неизменным данным. Методы включают разбитые структуры в слоистые или иерархические части для изоляции изменений, инвертирующие части конструкции, чтобы выставить дешевые обновления до часто модифицированных деталей, или даже хранить оригинальную структуру вместе с набором обновлений и объединения обновлений только с оригиналом на лету Когда данные доступны.
, так как вы используете F # здесь, я собираюсь предположить, что вы хотя бы несколько знакомы с C #; Невидимый Эрик ЛПППППТ имеет STOW POSTOUS на неизменяемых структурах данных в C #, которые, вероятно, будут хорошо просветить вас за пределами того, что я мог предоставить. В течение нескольких постов он демонстрирует (разумно эффективно) неизменные реализации стека, двоичного дерева и двойной очереди, среди прочего. Восхитительное чтение для любого программиста .NET!