Быстрый алгоритм вычисления процентилей для удаления выбросов
У меня есть программа, которая должна многократно вычислять приблизительный процентиль (статистику порядка) набора данных, чтобы удалить выбросы перед дальнейшей обработкой. В настоящее время я делаю это, сортируя массив значений и выбирая соответствующий элемент; это выполнимо, но это заметная ошибка в профилях, несмотря на то, что это довольно незначительная часть программы.
Дополнительная информация:
- Набор данных содержит порядка 100000 чисел с плавающей запятой, и предполагается, что он «разумно» распределен - маловероятно, что будут ни дубликаты, ни огромные всплески плотности около определенных значений; и если по какой-то нечетной причине распределение нечетное, это нормально, если приближение будет менее точным, поскольку данные, вероятно, так или иначе испорчены, и дальнейшая обработка сомнительна. Однако данные не обязательно распределены равномерно или нормально; просто очень маловероятно, что оно будет вырожденным.
- Приближенное решение было бы хорошо, но мне нужно понять , как приближение вносит ошибку, чтобы гарантировать его правильность.
- Поскольку цель состоит в том, чтобы удалить выбросы , Я всегда вычисляю два процентиля по одним и тем же данным: например, один с 95% и один с 5%.
- Приложение написано на C # с тяжелой работой на C ++; псевдокод или уже существующая библиотека в любом из них подойдут.
- Также подойдет совершенно другой способ удаления выбросов, если это разумно.
- Обновление: Кажется, я ищу приблизительный алгоритм выбора .
Хотя все это выполняется в цикле, данные каждый раз (немного) различаются, поэтому не так просто повторно использовать структуру данных, как это было сделано для этого вопроса .
Реализованное решение
Использование алгоритма выбора википедии, предложенного Гронимом, сократило эту часть времени выполнения примерно в 20 раз.
Поскольку я не смог найти реализацию C #, вот что я придумал. с участием. Это быстрее даже для небольших входных данных, чем Array.Sort; а при 1000 элементах это в 25 раз быстрее.
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
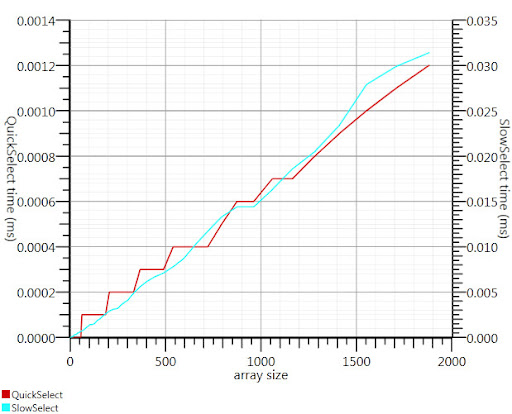
Спасибо, Гроним, за то, что указал мне в правильном направлении!