Проблема с операцией плавающей точки Точности в C
Для одного из моего проекта курса я начал реализовывать "Наивный байесовский классификатор" в C. Мой проект состоит в том, чтобы реализовать приложение классификатора документа (особенно Спам) использование огромных обучающих данных.
Теперь у меня есть проблема при реализации алгоритма из-за ограничений в типе данных C.
(Алгоритм, который я использую, дан здесь, http://en.wikipedia.org/wiki/Bayesian_spam_filtering),
ПРОБЛЕМНЫЙ ОПЕРАТОР: алгоритм вовлекает взятие каждого слова в документ и вычисление вероятности его являющийся словом спама. Если p1, p2 p3.... pn является вероятностями Word 1, 2, 3... n. Вероятность документа, являющегося спамом или не, вычисляется с помощью

Здесь, значение вероятности может быть очень легко приблизительно 0,01. Таким образом, даже если я буду использовать тип данных "дважды", то мое вычисление пойдет для броска. Для подтверждения этого, я написал код кода, данный ниже.
#define PROBABILITY_OF_UNLIKELY_SPAM_WORD (0.01)
#define PROBABILITY_OF_MOSTLY_SPAM_WORD (0.99)
int main()
{
int index;
long double numerator = 1.0;
long double denom1 = 1.0, denom2 = 1.0;
long double doc_spam_prob;
/* Simulating FEW unlikely spam words */
for(index = 0; index < 162; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom1 = denom1*(long double)(1 - PROBABILITY_OF_UNLIKELY_SPAM_WORD);
}
/* Simulating lot of mostly definite spam words */
for (index = 0; index < 1000; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom1 = denom1*(long double)(1- PROBABILITY_OF_MOSTLY_SPAM_WORD);
}
doc_spam_prob= (numerator/(denom1+denom2));
return 0;
}
Я попробовал Плавание, дважды и даже длинные двойные типы данных, но все еще ту же проблему.
Следовательно, скажите в 100K документе слов, который я анализирую, если всего 162 слова будут иметь 1%-ю вероятность спама, и оставление 99838 заметно слова спама, то все еще в моем приложении будет сказано это как Не документ Спама из-за ошибки Точности (поскольку числитель легко переходит к НУЛЮ)!!!.
Это - первый раз, когда я поражаю такую проблему. Таким образом, как точно этой проблемой нужно заняться?
6 ответов
Проблема вызвана тем, что вы собираете слишком много терминов без учета их размера. Одно из решений - логарифм. Другой - отсортировать ваши индивидуальные термины. Во-первых, давайте перепишем уравнение как 1 / p = 1 + ∏ ((1-p_i) / p_i) . Теперь ваша проблема в том, что одни термины маленькие, а другие большие. Если у вас слишком много маленьких терминов подряд, вы перегрузите, а со слишком большим количеством больших терминов вы перегрузите промежуточный результат.
Так что не ставьте слишком много подряд одного и того же порядка. Отсортируйте термины (1-p_i) / p_i . В результате первый член будет наименьшим, а последний - самым большим. Так вот, если бы вы сразу их умножили, у вас все равно был бы убыток. Но порядок расчета значения не имеет. Используйте два итератора во временной коллекции. Один начинается с начала (т.е. (1-p_0) / p_0 ), другой - в конце (например, (1-p_n) / p_n ), а ваш промежуточный результат начинается с 1,0 . Теперь, когда ваш промежуточный результат> = 1.0, вы берете член спереди, а когда ваш промежуточный результат <1.0, вы берете результат сзади.
В результате, когда вы берете термины, промежуточный результат будет колебаться около 1,0. Он будет только увеличиваться или уменьшаться по мере того, как у вас заканчиваются маленькие или большие сроки. Но это нормально. В этот момент вы использовали крайности на обоих концах, поэтому промежуточный результат будет постепенно приближаться к окончательному.
Конечно, существует реальная возможность переполнения.Если входные данные совершенно маловероятны, чтобы быть спамом (p = 1E-1000), тогда 1 / p переполнится, потому что ∏ ((1-p_i) / p_i) переполнится. Но поскольку термины отсортированы, мы знаем, что промежуточный результат будет переполняться только , если ∏ ((1-p_i) / p_i) переполняется. Таким образом, если промежуточный результат выходит за пределы, нет последующей потери точности.
Попробуйте вычислить обратное 1 / p. Это дает вам уравнение вида 1 + 1 / (1-p1) * (1-p2) ...
Если вы затем посчитаете возникновение каждой вероятности - похоже, что у вас небольшое количество значений которые повторяются - вы можете использовать функцию pow () - pow (1-p, occurences_of_p) * pow (1-q, occurences_of_q) - и избегайте отдельного округления при каждом умножении.
Я не силен в математике, поэтому не могу комментировать возможные упрощения формулы, которые могут устранить или уменьшить вашу проблему. Тем не менее, я знаком с ограничениями точности длинных двойных типов и знаю несколько математических библиотек произвольной и расширенной точности для C. Проверьте:
http://www.nongnu.org/hpalib/ {{ 1}} и http://www.tc.umn.edu/~ringx004/mapm-main.html
Вы можете использовать вероятность в процентах или промилях:
doc_spam_prob= (numerator*100/(denom1+denom2));
или
doc_spam_prob= (numerator*1000/(denom1+denom2));
или использовать другой коэффициент
Это часто случается в машинном обучении. AFAIK, вы ничего не можете поделать с потерей точности. Чтобы обойти это, мы используем функцию log и преобразуем деления и умножения в вычитание и сложение, соответственно.
Итак, я решил посчитать,
Исходное уравнение:

Я немного изменил его:
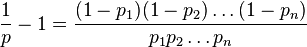
Взятие бревен с обеих сторон:

Пусть,

Подстановка,

Следовательно альтернативная формула для вычисления комбинированной вероятности:
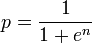
Если вам нужно, чтобы я расширил это, пожалуйста, оставьте комментарий.
Вот уловка:
for the sake of readability, let S := p_1 * ... * p_n and H := (1-p_1) * ... * (1-p_n),
then we have:
p = S / (S + H)
p = 1 / ((S + H) / S)
p = 1 / (1 + H / S)
let`s expand again:
p = 1 / (1 + ((1-p_1) * ... * (1-p_n)) / (p_1 * ... * p_n))
p = 1 / (1 + (1-p_1)/p_1 * ... * (1-p_n)/p_n)
Таким образом, вы получите произведение довольно больших чисел (от 0 до p_i = 0,01 , 99 ). Идея состоит не в том, чтобы перемножать тонны маленьких чисел друг на друга, чтобы получить, ну, 0 , а в том, чтобы сделать частное двух маленьких чисел. Например, если n = 1000000 и p_i = 0,5 для всех i , вышеуказанный метод даст вам 0 / (0 + 0) , что равно NaN , тогда как предлагаемый метод даст вам 1 / (1 + 1 * ... 1) , что составляет 0,5 .
Вы можете получить еще лучшие результаты, если все p_i отсортированы и вы объедините их в пары в противоположном порядке (предположим, p_1 <...
p = 1 / (1 + (1-p_1)/p_n * ... * (1-p_n)/p_1)
таким образом вы разделите большие числители (маленькие p_i ) на большие знаменатели (большие p_ (n + 1-i) ) и маленькие числители с малыми знаменателями.
править: MSalter предложил полезную дополнительную оптимизацию в своем ответе. Используя его, формула выглядит следующим образом:
p = 1 / (1 + (1-p_1)/p_n * (1-p_2)/p_(n-1) * ... * (1-p_(n-1))/p_2 * (1-p_n)/p_1)