решение OCR / ежедневно перерывает 4 миллиона листков бумаги и 10 000 добавляемых
Я работаю на медицинскую компанию лаборатории. Они должны смочь перерыть все свои клиентские данные. До сих пор у них есть несколько лет в устройстве хранения данных приблизительно 4 миллиона листков бумаги, и они добавляют 10 000 страниц в день. Для данных, которые 6 месяцев, они должны получить доступ к нему приблизительно 10-20 раз в день. Они решают, потратить ли 80k на систему сканирования, и сделайте, чтобы секретари просканировали все в доме, или нанять ли компанию как Айен-Маунтин, чтобы сделать это. Айен-Маунтин будет заряжать приблизительно 8 центов за страницу, который составляет в целом приблизительно 300 тысяч $ для количества бумаги, которую мы имеем плюс набор большего количества денег каждый день для 10 000 листов.
Я думаю, что, возможно, могу создать базу данных и сделать все сканирование в доме.
- Каковы те системы, которые используются для сканирования проверок и почты, и они читают действительно грязную руку, пишущую действительно хорошо?
- у кого-либо был опыт при создании базы данных с набором доступных для поиска документов OCR'd? Какие инструменты я должен использовать для своей проблемы?
- Можно ли рекомендовать лучшие библиотеки OCR?
- Как программист, что Вы сделали бы для решения этой проблемы?
К вашему сведению ни один из ответов ниже не отвечает на мои вопросы достаточно хорошо
10 ответов
Разделяй и властвуй!
Если вы все же решите пойти по пути «своими силами». Ваш проект должен иметь масштабируемость с первого дня.
Это тот редкий случай, когда задача может быть разбита и выполнена параллельно .
Если у вас есть 10K документов, даже если вы создали и развернули 10x (сканеры + серверы + пользовательское приложение), это будет означать, что каждой системе потребуется обрабатывать только около 1k документов каждая.
Задача состоит в том, чтобы сделать его дешевым и надежным «решением под ключ» .
Приложение, вероятно, является более простым элементом, если у вас есть хорошая система автоматического обновления, разработанная с самого начала, вы можете просто добавлять оборудование по мере расширения своей «фермы / кластера».
Сохранение модульной конструкции (т. Е. Использование дешевого оборудования) позволит вам комбинировать и подбирать оборудование / заменять его по требованию, не влияя на ежедневную пропускную способность.
Первоначально попытаться получить решение «под ключ», способное легко выдержать 1000 документов. Затем, как только это сработает безупречно, увеличьте масштаб!
Удачи!
Редактировать 1:
Хорошо, вот более подробный ответ на каждый конкретный вопрос, который вы подняли:
Какие это системы, которые используются для сканирования чеков и почты, и они читай действительно грязный почерк, правда ну?
Одна из таких систем, которая используется компанией TNT по доставке почты здесь, в Великобритании, предоставляется нидерландской компанией Prime Vision и их HYCR Двигатель.
Я настоятельно рекомендую вам связаться с ними. Распознавание рукописного текста никогда не будет очень точным, OCR напечатанных символов иногда может достигать 99% точности.
есть ли у кого-нибудь опыт создания базы данных с помощью множества оптических распознавателей текста. доступные для поиска документы? Какие инструменты следует ли мне использовать для решения своей проблемы?
Не специально для OCR-документов, но для одного из наших клиентов я создаю и поддерживаю очень большую и сложную EDMS, которая содержит очень большое разнообразие форматов документов. Он доступен для поиска несколькими способами со сложным набором разрешений доступа к данным.
Говоря о совете, я бы сказал несколько вещей, о которых следует помнить:
- Хранить документы в файле и иметь ссылку в базе данных
- Хранить документ непосредственно в базе данных как данные BLOB.
У каждого подхода есть свои плюсы и минусы. Мы выбрали первый маршрут. Что касается возможности поиска, если у вас есть метаданные реальных документов. Это просто вопрос создания пользовательских поисковых запросов. Я построил поиск на основе ранга, он просто давал более высокий рейтинг тем, которые соответствовали большему количеству токенов. Конечно, вы можете использовать инструменты поиска на полке (библиотеку), такие как Lucene Project .
Можете ли вы порекомендовать лучшее распознавание текста? библиотеки?
да:
Как программист, что бы вы сделали с решить эту проблему?
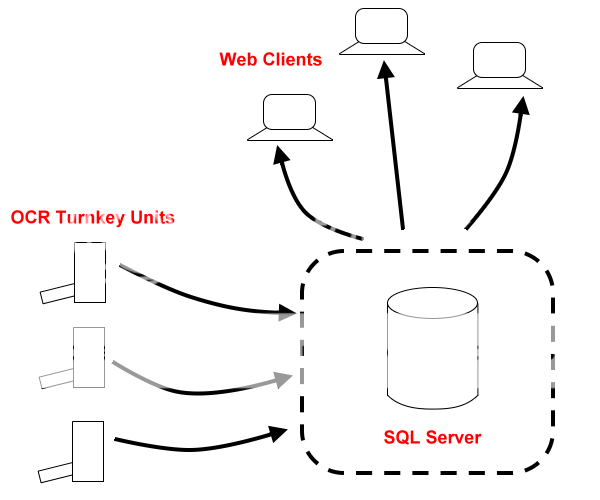
Как описано выше, см. диаграмму ниже. Сердцем системы будет ваша база данных, вам понадобится передний уровень представления, чтобы клиенты (например, веб-приложение) могли искать документы в вашей базе данных. Вторая часть - это «серверы» OCR под ключ.
Для этих «серверов OCR» я бы просто реализовал «папку для размещения» (которая может быть папкой FTP). Ваше пользовательское приложение может просто отслеживать эту папку (класс Folder Watcher в .NET). Файлы можно отправлять прямо в эту FTP-папку.
Ваше настраиваемое приложение OCR будет просто отслеживать перетаскиваемую папку и, получив новый файл, сканировать его, генерировать метаданные, а затем перемещать его в «Отсканированную» папку ».Те, которые являются дубликатами или не были просканированы, могут быть перемещены в их собственную «Неудачную папку».
Приложение OCR затем подключится к вашей основной базе данных и выполнит некоторые вставки или обновления (это перемещает МЕТА ДАННЫЕ в основную базу данных).
В фоновом режиме вы можете синхронизировать вашу «Отсканированную папку» с зеркальной папкой на вашем сервере базы данных (ваш SQL-сервер, как показано на диаграмме) (Это затем физически копирует ваш отсканированный и OCR-документ на главный сервер, где связанные записи уже были перемещены.)
В любом случае, я бы решил эту проблему именно так. Я лично реализовал одно или несколько из этих решений, поэтому уверен, что это сработает и будет масштабируемым.
Ключевым моментом здесь является масштабируемость. По этой причине вы можете захотеть взглянуть на альтернативную базу данных, отличную от традиционных.
Я бы порекомендовал вам хотя бы подумать о базе данных типа NoSQL для этого проекта:
Например,
Un-ashamed Plug:
Конечно, за 40 000 фунтов стерлингов я бы построил и настроил для вас все решение (включая оборудование)!
:) Шучу ТАК пользователи!
РЕДАКТИРОВАТЬ 2:
Обратите внимание на упоминание МЕТА ДАННЫХ , под этим я подразумеваю то же, что и другие. Тот факт, что вы должны сохранить исходную копию отсканированного изображения в виде файла изображения вместе с метаданными OCR (чтобы можно было выполнять поиск по тексту).
Я подумал, что проясню это на случай, если предполагалось, что это не было частью моего решения.
Вы никак не сможете найти программное обеспечение OCR, которое будет надежно читать почерк, особенно почерк, который вы бы назвали "грязным".
Вы можете потратить много денег на систему сканирования, но это будет очень дорого и очень быстро (не менее $15 тыс. за сканер высокого класса, плюс стоимость программного обеспечения, обучения и т.д.). А без надежного OCR вам также придется вручную вводить все данные, которые вы хотите получить из каждого документа. Очевидно, что это значительно увеличит ваши расходы (дополнительное программное обеспечение, дополнительные сотрудники и т.д.), не говоря уже о том, что время выполнения заказа с момента создания новых документов до момента, когда они будут доступны пользователям, может оказаться неприемлемым для ежедневного объема, о котором вы говорите.
Вам лучше отправить все свои документы в такую компанию, как Iron Mountain. При том объеме, о котором вы говорите, и при условии, что документы, которые вы хотите отсканировать/набрать ключ, не слишком сложны, я буду удивлен, если вы не сможете получить лучшую цену, чем $.08 за страницу.
Такая компания может предоставить ваши изображения и данные для импорта в какое-либо программное обеспечение для управления документами, или вы можете написать собственное приложение.
обновление
используя идею @eykanal в качестве отправной точки
примерами метаданных, которые вы будете хранить, могут быть идентификатор документа, местоположение исходного изображения и то, по чему можно найти запись (идентификатор пациента, ssn или имя и т.д.). Данные "локатора записи", вероятно, должны будут вводиться сотрудниками службы ввода данных, которые будут смотреть на физическую форму при ее сканировании.
оригинал:
- Не уверен, как называются устройства для чтения чеков, но (по крайней мере, для чеков) они ищут только цифры, поэтому при таком ограниченном наборе символов они гораздо точнее, чем обычный OCR.
Одна вещь, о которой следует подумать:
Возьмите 10 секунд в качестве приблизительного времени сканирования одной страницы.
Тогда 10,000 * 10 / 60 /60 = ~27.8 часов для сканирования вашего ежедневного набора.
Это означает, что более трех сотрудников, занятых полный рабочий день, ОБЯЗАНЫ сканировать каждый день. Это может устраивать вас и вашего работодателя, но я бы предположил, что дешевле отдать сканирование на аутсорсинг. Даже 3 низкооплачиваемых сотрудника вместе с пособиями и т.д. будут стоить > 100 тыс. в год.
Также:
В прошлом опыте работы с xerox doc сканерами, они давали около 50-100k данных изображения на страницу, в зависимости от настроек и без учета текста OCR. Учитывая, что вы говорите о медицинских записях, вам, вероятно, придется хранить и их (я могу представить себе юридические проблемы, если вы этого не сделаете). Это означает от 200 до 400 гигов для того, что у вас есть, плюс от 1/2 до 1 гига в день.
OCR-ить записи врачей не так-то просто :D
Попробуйте выяснить, какие из этих 4M страниц нужны немедленно, и наймите Iron mountain для этих страниц.
Что касается остального, сообщите клиенту, что перед вами поставлена невыполнимая задача, и попытайтесь найти практическое решение - может быть, они могут просто ввести небольшую часть этих бумаг и полагаться на статистику?
На будущее, если вы сможете отформатировать информацию в виде множественного выбора, что-то вроде Scantron может стать доступным решением.
Если вы работали в медицинском офисе над вводом данных, OCR почти наверняка не будет работать. В наших формах были специальные текстовые поля с отдельным полем для каждой буквы, и даже для этого программное обеспечение было правильным только в 75% случаев. Были некоторые формы, которые позволяли писать в произвольной форме, но в результате повсеместно получалось бессмысленно.
Я бы рекомендовал пойти по маршруту метаданных; сканировать все, но вместо того, чтобы пытаться распознавать каждую форму, просто сохраните ее как изображение и добавьте теги метаданных.
Я считаю, что цель OCR в данном случае - дать возможность всем формам считываться с компьютера, что упростит извлечение данных. Однако для этого здесь не требуется OCR, все, что вам нужно сделать, это найти способ, который позволил бы кому-то очень быстро найти форму и получить нужную информацию из формы. Таким образом, даже если вы сохраняете каждую форму как изображение, добавление правильных тегов метаданных позволит вам извлекать все, что вам нужно, когда вам это нужно, и человек, выполняющий поиск, может либо прочитать его прямо из сохраненной формы, либо распечатайте и прочтите так.
РЕДАКТИРОВАТЬ: Одним из довольно простых способов выполнения этого плана может быть использование простой схемы базы данных, где каждое изображение хранится как одно поле. Каждая строка может содержать что-то вроде следующего, в зависимости от ваших потребностей:
- имя изображения
- идентификатор пациента
- дата посещения
- ...
В принципе, подумайте обо всех способах поиска данного файла и убедитесь, что он включен как поле. Вы ищете пациентов по идентификатору пациента? Включите это. Дата посещения? Такой же. Если вы не знакомы с проектированием базы данных с учетом требований поиска, я предлагаю нанять разработчика, обладающего навыками проектирования баз данных; вы можете получить очень мощную, но быструю схему базы данных, которая включает в себя все, что вы хотите, и достаточно мощную для ваших нужд индексирования. (Имейте в виду, что многое из этого будет очень специфичным для вашего приложения. Вы захотите оптимизировать это для своей ситуации и с самого начала убедитесь, что настроили как можно лучше.)
На мой взгляд, самая большая проблема - это получить бумагу в цифровом виде.
Когда у вас есть изображения, я могу придумать два решения (или лучшие идеи).
Напишите приложение (не веб-приложение !!!), которое будет показывать изображения секретарям одно за другим. Секретари помечают изображения ссылкой на изображение, и эти теги хранятся в базе данных. Пользовательский интерфейс должен быть очень хорошо спроектирован (не время загрузки, функция автоматического угадывания ...), чтобы обеспечить максимальную скорость работы.
(мое любимое) Используйте программу оптического распознавания текста, чтобы сканировать изображения и получать доступный для поиска текст. Затем создайте приложение, которое построит дерево слов, используемых в документах. Каждое слово должно иметь ссылки на документы, к которым оно принадлежит. Слова вроде (в ан из ...) следует исключить из дерева. Тогда вы можете очень быстро поискать в дереве и найти документы. Если вы хотите сопоставить группы слов, ищите каждое слово и пересекайте результаты.Чтобы выполнить более продвинутый поиск, бросьте текст с дырой, я бы порекомендовал модифицированную версию DFA, которая может обрабатывать один символ данных, используя только дешевые инструкции, такие как поиск в таблице (очень продвинутый, я знаю это из-за моего интереса к дизайну компилятора) ... он должен можно будет сканировать текстовые данные (на уровне ГБ) в приемлемое время ...
Это всего лишь предложения !!!!! Просто подумал ... Может есть что полезное!
Лучшее программное обеспечение для распознавания текста, которое я когда-либо видел в своей жизни, называется ABBYY: http://www.abbyy.com/company
У меня есть их программное обеспечение, и я использую его в дом для проектов, связанных с работой. Он будет сканировать документы, даже документы с графикой, такие как логотипы, флажки и т. Д., И конвертировать полученный документ в Microsoft Word или PDF. Это наиболее распространенный экспорт. Независимо от того, что он не может преобразовать в текст (например, логотип), он просто создаст графическое изображение и поместит его в документ.
Что касается того, как это делает почта, они используют специальное программное обеспечение для распознавания текста (вероятно, ABBYY), которое может распознавать рукописный ввод: http://en.wikipedia.org/wiki/Remote_Bar_Coding_System
ABBYY также имеет SDK, поэтому, если вы хотите написать собственное приложение и интегрировать в него OCR, вы тоже можете это сделать!
Как уже предлагали другие, ваша ситуация в значительной степени представляет собой стандартную проблему ECM (управление корпоративным контентом) / архивирование.
Обычно это выполняется с помощью «платформы сканирования» (в зависимости от объема, большие, вероятно, будут чем-то вроде EMC² Captiva или Kofax, или они могут быть выполнены за пределами площадки, как вы уже указали) для сканирования бумажные документы и хранить цифровые документы в каком-либо репозитории. Этот репозиторий традиционно является платформой ECM, такой как Documentum (EMC²), FileNet (IBM), OpenText, ... Эти платформы будут предлагать вам все виды функций для использования в сочетании с вашими цифровыми документами, включая полнотекстовый поиск . Конечно, у всего вышеперечисленного есть свой ценник.
Чтобы высказать свое мнение по вашим конкретным вопросам:
- Что это за системы, которые используются для сканирования чеков и почты, и они действительно хорошо читают грязный почерк?
Что ж, подойдет любое решение для сканирования. Я не эксперт в сканировании, но сомневаюсь, что какое-либо из этих решений даст хорошие результаты при написании от руки.
- Был ли у кого-нибудь опыт создания базы данных с набором документов, доступных для поиска с помощью оптического распознавания текста? Какие инструменты мне следует использовать для решения моей проблемы?
Нет. Но это то, что репозитории ECM сделают за вас. Существуют альтернативы, в первую очередь Apache Lucene ( http: //lucene.apache.org ) в мире Java.
- Можете ли вы порекомендовать лучшие библиотеки OCR?
Как упоминалось ранее, единственная известная мне библиотека OCR, которая дает неплохие результаты, - это ABBYY.
- Как программист, что бы вы сделали для решения этой проблемы?
Если вам не нужен ECM, и вы уверены, что в будущем вам не понадобятся дополнительные функции, предоставляемые платформой ECM, тогда стоит задуматься о создании чего-то нестандартного. Маловероятно, что это будет легко и просто, поэтому вам придется потратить много времени на его проектирование, и имейте в виду, что сохранить что-то вроде этого масштабируемого будет нелегкой задачей.
Бесплатный загрузочный OCR сервер: http://www.watchocr.com/
As featureded on slashdot: http://linux.slashdot.org/story/10/07/22/1852234/Open-Source-OCR-That-Makes-Searchable-PDFs
Стоит хотя бы попробовать.
В настоящее время вы решаете не ту проблему, и 300 тысяч - это арахис, как уже показали другие. Вам следует сосредоточиться на устранении 10K страниц в день, которые вы получаете сейчас. Другая проблема требует фиксированной суммы денег.
OCR надежно работает только для почерка в очень ограниченных областях (распознавание банковских номеров, почтовых индексов). Прекрасные результаты, которые рекламируют компании OCR, относятся к печатным компьютерным документам стандартных форматов и стандартных шрифтов.
Ввод данных не должен осуществляться на бумаге. Точка. Сосредоточьтесь на том, чтобы сделать это именно так. Загоните проблему вперед.
И да, это не проблема программистов. Это проблема менеджмента.