Последовательное добавление символа для получения самого долгого слова в [закрытом] словаре
3 ответа
Метод грубой силы заключается в том, чтобы попытаться добавить буквы в каждый доступный индекс с помощью поиска в глубину.
Итак, начиная с «а», есть два места, где вы можете добавить новую букву. Перед или за буквой «а», представленной точками внизу.
.a.
Если вы добавите букву «т», то теперь будет три позиции.
.a.t.
Вы можете попробовать добавить все 26 букв в каждую доступную позицию. Словарь в этом случае может быть простой хеш-таблицей. Если вы добавите букву «z» посередине, вы получите «азт», которого не будет в хеш-таблице, поэтому вы не продолжите поиск по этому пути.
Править : Граф Ника Джонсона заставил меня задуматься, как будет выглядеть график всех максимальных путей. Это большое (1,6 МБ) изображение здесь:
http://www.michaelfogleman.com/static/images/word_graph.png
{kind=link}
Правка : Вот реализация Python. Подход грубой силы фактически выполняется за разумное время (несколько секунд, в зависимости от начальной буквы).
import heapq
letters = 'abcdefghijklmnopqrstuvwxyz'
def search(words, word, path):
path.append(word)
yield tuple(path)
for i in xrange(len(word)+1):
before, after = word[:i], word[i:]
for c in letters:
new_word = '%s%s%s' % (before, c, after)
if new_word in words:
for new_path in search(words, new_word, path):
yield new_path
path.pop()
def load(path):
result = set()
with open(path, 'r') as f:
for line in f:
word = line.lower().strip()
result.add(word)
return result
def find_top(paths, n):
gen = ((len(x), x) for x in paths)
return heapq.nlargest(n, gen)
if __name__ == '__main__':
words = load('TWL06.txt')
gen = search(words, 'b', [])
top = find_top(gen, 10)
for path in top:
print path
Конечно, в ответе будет много завязок. Это напечатает первые N результатов, измеренных длиной последнего слова.
Вывод для начальной буквы 'a' с использованием словаря TWL06 Scrabble.
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampeder', 'stampeders'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'estranges', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangers', 'stranglers'))
А вот результаты для каждой начальной буквы. Конечно, делается исключение, что единственная начальная буква не обязательно должна быть в словаре. Просто какое-то двухбуквенное слово, которое может быть образовано с его помощью.
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(9, ('b', 'bo', 'bos', 'bods', 'bodes', 'bodies', 'boodies', 'bloodies', 'bloodiest'))
(1, ('c',))
(10, ('d', 'od', 'cod', 'coed', 'coped', 'comped', 'compted', 'competed', 'completed', 'complected'))
(10, ('e', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(9, ('f', 'fe', 'foe', 'fore', 'forge', 'forges', 'forgoes', 'forgoers', 'foregoers'))
(10, ('g', 'ag', 'tag', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(9, ('h', 'sh', 'she', 'shes', 'ashes', 'sashes', 'slashes', 'splashes', 'splashers'))
(11, ('i', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(7, ('j', 'jo', 'joy', 'joky', 'jokey', 'jockey', 'jockeys'))
(9, ('k', 'ki', 'kin', 'akin', 'takin', 'takins', 'takings', 'talkings', 'stalkings'))
(10, ('l', 'la', 'las', 'lass', 'lassi', 'lassis', 'lassies', 'glassies', 'glassines', 'glassiness'))
(10, ('m', 'ma', 'mas', 'mars', 'maras', 'madras', 'madrasa', 'madrassa', 'madrassas', 'madrassahs'))
(11, ('n', 'in', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(10, ('o', 'os', 'ose', 'rose', 'rouse', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(11, ('p', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(3, ('q', 'qi', 'qis'))
(10, ('r', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('s', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('t', 'ti', 'tin', 'ting', 'sting', 'sating', 'stating', 'estating', 'restating', 'restarting'))
(10, ('u', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(1, ('v',))
(9, ('w', 'we', 'wae', 'wake', 'wakes', 'wackes', 'wackest', 'wackiest', 'whackiest'))
(8, ('x', 'ax', 'max', 'maxi', 'maxim', 'maxima', 'maximal', 'maximals'))
(8, ('y', 'ye', 'tye', 'stye', 'styed', 'stayed', 'strayed', 'estrayed'))
(8, ('z', 'za', 'zoa', 'zona', 'zonae', 'zonate', 'zonated', 'ozonated'))
Предполагая, что вам нужно делать это несколько раз (или вы хотите получить ответ для каждой из 26 букв), сделайте это в обратном порядке:
- Загрузите словарь , и отсортируйте его по длине по убыванию
- Установите отображение, изначально пустое, между словами и (extension, max_len) кортежами.
- Для каждого слова в отсортированном списке:
- Если оно уже присутствует в сопоставлении, получить максимальную длину.
- Если это не так, установите max len равным длине слова.
- Изучите каждое слово, полученное при удалении символа.Если этого слова нет в сопоставлении или наше max_len превышает max_len слова, уже находящегося в сопоставлении, обновите сопоставление текущим словом и max_len
Затем, чтобы получить цепочку для данного префикса, просто начните с этого префикс и несколько раз посмотрите его и его расширения в словаре.
Вот пример кода Python:
words = [x.strip().lower() for x in open('/usr/share/dict/words')]
words.sort(key=lambda x:len(x), reverse=True)
word_map = {} # Maps words to (extension, max_len) tuples
for word in words:
if word in word_map:
max_len = word_map[word][1]
else:
max_len = len(word)
for i in range(len(word)):
new_word = word[:i] + word[i+1:]
if new_word not in word_map or word_map[new_word][2] < max_len:
word_map[new_word] = (word, max_len)
# Get a chain for each letter
for term in "abcdefghijklmnopqrstuvwxyz":
chain = [term]
while term in word_map:
term = word_map[term][0]
chain.append(term)
print chain
И его результат для каждой буквы алфавита:
['a', 'ah', 'bah', 'bach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['b', 'ba', 'bac', 'bach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['c', 'ca', 'cap', 'camp', 'campo', 'campho', 'camphor', 'camphory', 'camphoryl', 'camphoroyl']
['d', 'ad', 'cad', 'card', 'carid', 'carida', 'caridea', 'acaridea', 'acaridean']
['e', 'er', 'ser', 'sere', 'secre', 'secret', 'secreto', 'secretor', 'secretory', 'asecretory']
['f', 'fo', 'fot', 'frot', 'front', 'afront', 'affront', 'affronte', 'affronted']
['g', 'og', 'log', 'logy', 'ology', 'oology', 'noology', 'nosology', 'nostology', 'gnostology']
['h', 'ah', 'bah', 'bach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['i', 'ai', 'lai', 'lain', 'latin', 'lation', 'elation', 'delation', 'dealation', 'dealbation']
['j', 'ju', 'jug', 'juga', 'jugal', 'jugale']
['k', 'ak', 'sak', 'sake', 'stake', 'strake', 'straked', 'streaked']
['l', 'la', 'lai', 'lain', 'latin', 'lation', 'elation', 'delation', 'dealation', 'dealbation']
['m', 'am', 'cam', 'camp', 'campo', 'campho', 'camphor', 'camphory', 'camphoryl', 'camphoroyl']
['n', 'an', 'lan', 'lain', 'latin', 'lation', 'elation', 'delation', 'dealation', 'dealbation']
['o', 'lo', 'loy', 'logy', 'ology', 'oology', 'noology', 'nosology', 'nostology', 'gnostology']
['p', 'pi', 'pig', 'prig', 'sprig', 'spring', 'springy', 'springly', 'sparingly', 'sparringly']
['q']
['r', 'ra', 'rah', 'rach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['s', 'si', 'sig', 'spig', 'sprig', 'spring', 'springy', 'springly', 'sparingly', 'sparringly']
['t', 'ut', 'gut', 'gutt', 'gutte', 'guttle', 'guttule', 'guttulae', 'guttulate', 'eguttulate']
['u', 'ut', 'gut', 'gutt', 'gutte', 'guttle', 'guttule', 'guttulae', 'guttulate', 'eguttulate']
['v', 'vu', 'vum', 'ovum']
['w', 'ow', 'low', 'alow', 'allow', 'hallow', 'shallow', 'shallowy', 'shallowly']
['x', 'ox', 'cox', 'coxa', 'coxal', 'coaxal', 'coaxial', 'conaxial']
['y', 'ly', 'loy', 'logy', 'ology', 'oology', 'noology', 'nosology', 'nostology', 'gnostology']
['z', 'za', 'zar', 'izar', 'izard', 'izzard', 'gizzard']
Редактировать: Учитывая степень слияния ветвей к концу, я подумал, что было бы интересно нарисовать график, чтобы продемонстрировать this:
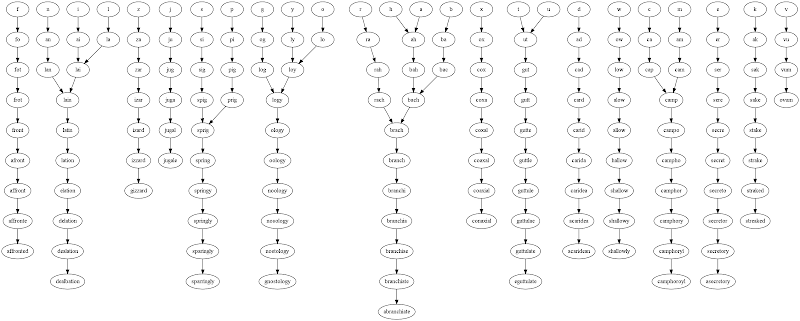
Интересное расширение этой задачи: вероятно, есть несколько заключительных слов равной длины для некоторых букв. Какой набор цепочек минимизирует количество конечных узлов (например, объединяет наибольшее количество букв)?
Если вы хотите сделать это один раз, я бы сделал следующее (обобщенно для проблемы начала с полного слова):
Возьмите свой весь словарь и выбросьте все, что не содержит надмножества символов в вашем целевом слове (скажем, оно имеет длину м ). Затем разделите оставшиеся слова по длине. Для каждого слова длиной m + 1 попробуйте отбросить каждую букву и посмотреть, дает ли это желаемое слово. Если нет, выбросьте это. Затем проверьте каждое слово длины m + 2 на соответствие действительному набору длины m + 1 , отбрасывая любое слово, которое не может быть уменьшено. Продолжайте идти, пока не найдете пустой набор; последнее, что вы нашли, будет самым длинным.
Если вы хотите ускорить поиск, я бы построил суффикс-дерево - подобную структуре данных .
Сгруппируйте все слова по длине. Для каждого слова длиной 2 поместите каждый из двух его символов в набор «подслов» и добавьте это слово к каждому из наборов «сверхслов». Теперь у вас есть связь между всеми допустимыми словами длиной 2 и всеми символами. Сделайте то же самое со словами длины 3 и допустимыми словами длины 2. Теперь вы можете начать с любого места в этой иерархии и выполнить поиск в ширину, чтобы найти самую глубокую ветвь.
Изменить: скорость этого решения будет сильно зависеть от структуры языка, но если мы решим построить все, используя наборы с log (n) производительностью для всех операций (т.е.мы используем красно-черные деревья или что-то подобное), и у нас есть N (m) слов длины m , чтобы затем сформировать связь между словами длины m + 1 и m будут приблизительно (m + 1) * m * N (m + 1) * log (N (m)) времени (с учетом сравнения строк, линейное время по длине струны). Поскольку мы должны сделать это для всех длин слов, время выполнения для построения полной структуры данных будет примерно
(typical word length)^3 * (dictionary length) * log (dictionary length / word length)
(начальное разделение на слова определенной длины займет линейное время, поэтому им можно пренебречь; фактическое формула для времени выполнения сложна, потому что она зависит от распределения длин слов; в случае, когда вы делаете это из одного слова, она еще более сложна, потому что она зависит от ожидаемого количества более длинных слов с более короткими подсловами.)