Нахождение Счета Достижимости для всех вершин DAG
Я пытаюсь найти, что алгоритм FAST со скромными необходимыми площадями решает следующую проблему.
Поскольку каждая вершина DAG находит сумму своего в градусе и-градуса в переходном закрытии DAG.
Учитывая этот DAG:
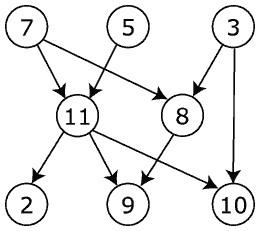
Я ожидаю следующий результат:
Vertex # Reacability Count Reachable Vertices in closure
7 5 (11, 8, 2, 9, 10)
5 4 (11, 2, 9, 10)
3 3 (8, 9, 10)
11 5 (7, 5, 2, 9, 10)
8 3 (7, 3, 9)
2 3 (7, 5, 11)
9 5 (7, 5, 11, 8, 3)
10 4 (7, 5, 11, 3)
Мне кажется, что это должно быть возможно, на самом деле не создавая переходное закрытие. Я не смог найти что-либо в сети, которая точно описывает эту проблему. Я получил некоторое представление о том, как сделать это, но я хотел видеть то, что, ТАКИМ ОБРАЗОМ, могла придумать толпа.
5 ответов
Я создал жизнеспособное решение этого вопроса. Я основываю свое решение на модификации алгоритма топологической сортировки. Приведенный ниже алгоритм вычисляет только внутреннюю степень в транзитивном замыкании. Степень выхода может быть вычислена таким же образом с перевернутыми ребрами и суммированием двух подсчетов для каждой вершины для определения окончательного "подсчета достижимости".
for each vertex V
inCount[V] = inDegree(V) // inDegree() is O(1)
if inCount[V] == 0
pending.addTail(V)
while pending not empty
process(pending.removeHead())
function process(V)
for each edge (V, V2)
predecessors[V2].add(predecessors[V]) // probably O(|predecessors[V]|)
predecessors[V2].add(V)
inCount[V2] -= 1
if inCount[V2] == 0
pending.add(V2)
count[V] = sizeof(predecessors[V]) // store final answer for V
predecessors[V] = EMPTY // save some memory
Предполагая, что операции над множествами имеют порядок O(1), этот алгоритм выполняется за O(|V| + |E|). Однако более вероятно, что операция объединения множеств predecessors[V2].add(predecessors[V]) делает его несколько хуже. Дополнительные шаги, требуемые объединением множеств, зависят от формы DAG. Я считаю, что в худшем случае это O(|V|^2 + |E|). В моих тестах этот алгоритм показал лучшую производительность, чем любой другой, который я пробовал до сих пор.
Более того, благодаря утилизации наборов предшественников для полностью обработанных вершин, этот алгоритм обычно использует меньше памяти, чем большинство альтернатив. Правда, в худшем случае потребление памяти вышеуказанным алгоритмом совпадает с потреблением памяти при построении транзитивного замыкания, но для большинства DAG это не так.
OMG ЭТО НЕПРАВИЛЬНО! ПРОСТИТЕ!
Я оставлю это до тех пор, пока не появится хорошая альтернатива. CW-ed так что не стесняйтесь обсуждать и расширять это, если возможно.
Используйте динамическое программирование.
for each vertex V
count[V] = UNKNOWN
for each vertex V
getCount(V)
function getCount(V)
if count[V] == UNKNOWN
count[V] = 0
for each edge (V, V2)
count[V] += getCount(V2) + 1
return count[V]
Это O(|V|+|E|) со списком смежности. Он подсчитывает только исходящие степени в транзитивном замыкании. Для подсчета входящих степеней вызовите getCount с перевернутыми ребрами. Чтобы получить сумму, сложите значения обоих вызовов.
Чтобы понять, почему это O(|V|+|E|), рассмотрим следующее: каждая вершина V будет посещена ровно 1 + in-degree(V) раз: один раз непосредственно на V, и один раз для каждого ребра (*, V). При последующих посещениях getCount(V) просто возвращает мемоизированный count[V] за O(1).
Другой способ посмотреть на это - посчитать, сколько раз каждое ребро будет пройдено вдоль: ровно один раз.
Для каждого узла используйте BFS или DFS, чтобы найти недостижимость.
Сделайте это снова для обратного направления, чтобы найти внутреннюю достижимость.
Временная сложность: O(MN + N2), сложность пространства: O(M + N).
Я предполагаю, что у вас есть список всех вершин, и что каждая вершина имеет id и список вершин, к которым вы можете напрямую добраться.
Затем вы можете добавить другое поле (или как вы его представляете), которое содержит вершины, к которым вы также можете косвенно добраться. Я бы сделал это в рекурсивном поиске в глубину, запоминая результаты в области соответствующих достигнутых узлов. В качестве структуры данных для этого вы, возможно, использовали бы какое-то дерево, которое позволяет эффективно удалять дубликаты.
Доступность можно сделать отдельно, добавив обратные ссылки, но это также можно сделать на том же проходе, что и недоступность, путем накопления текущих выходящих узлов и добавления их в соответствующие поля достиг узлов.
Чтобы получить точный ответ, я думаю, что будет сложно превзойти алгоритм КенниTM. Если вы готовы согласиться на приблизительное значение, тогда может помочь метод подсчета танков ( http://www.guardian.co.uk/world/2006/jul/20/secondworldwar.tvandradio ).
Присвойте каждой вершине случайное число в диапазоне [0, 1). Используйте динамическую программу с линейным временем, такую как polygenelubricants, для вычисления для каждой вершины v минимального числа minreach (v), достижимого из v. Затем оцените количество вершин, достижимых из v, как 1 / minreach (v) - 1. Для большей точности повторите несколько раз и возьмите среднее значение в каждой вершине.