Представление кода алгебраически
У меня есть много маленьких алгоритмов, которые я хотел бы описать в газете. Они относительно коротки, и кратки. Однако вместо того, чтобы писать им в псевдокоде (а-ля Cormen или даже Knuth), я хотел бы записать алгебраическое представление их (больше линейного и лучшего ЛАТЕКСНОГО рендеринга). Однако я не могу найти ресурсы относительно лучшей нотации для этого, если существует что-нибудь: например, как я представляю цикл? Если? Добавление кортежа к списку?
Какой-либо из Вас встретился с этой проблемой и так или иначе решил ее?
Спасибо.
Править: Спасибо, люди. Я думаю, что сделал плохое задание при формулировке вопроса. Здесь идет снова, надеясь, что я делаю это более ясным: какова общая нотация для разговора о циклах и если затем пункты в математической нотации? Например, я могу использовать $acc \leftarrow acc \cup \langle i,i+1 \rangle$ представить "добавить" метод списка.
8 ответов
Я вижу, если-выражения в математическом обозначении довольно часто. Обычная вещь для цикла является соотношение рецидивов или эквивалентно, функция определена рекурсивно.
Вот как функция функция Ackermann определяется в Wikipedia, например:
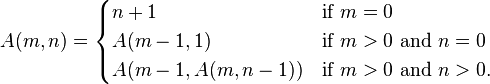
эта картина приглашается, потому что оно чувствует математическую в аромате, и все же вы могли бы явно вводить его почти точно так же, как написано и имеют выполнение. Не всегда возможно достичь этого.
Другие математические обозначения, которые соответствуют петлям, включают σ-нотацию для суммирования и Обозначение установленного строителя .
Я надеюсь, что это отвечает на ваш вопрос! Но если ваша цель - описать, как что-то сделано и у кого-то понимают, я думаю, что это, вероятно, ошибка предположить, что математики предпочли бы видеть уравнения. Я не думаю, что они взаимозаменяемые инструменты (несмотря на то, что вытесняет эквивалентность). Если ваш алгоритм включает в себя союзные структуры данных, процедурный код, вероятно, будет лучше, чем уравнения для объяснения его.
Я скопирую кнуту. Немногие знают, как общаться лучше, чем он в настройке компьютерных наук.
Вы можете взглянуть на Haskell. Haskell Formatats Хорошо в LaTex, имеет хороший алгебраический синтаксис, и вы даже можете компилировать файл латекса с Haskell в нем, при условии, что код завернут в \ Begin {Code} и \ end {код } . Смотрите здесь: http://www.haskell.org/haskellwiki/literate_programming . Вероятно, есть грамотные инструменты программирования для других языков.
Могу ли я предложить: проект mono и Монодевосло как бесплатная альтернатива Visual Studio. Вы можете запустить монодепов на Windows, Mac и Linux!
-121--4096783-Lisp начался как математическая обозначение вычислительной модели, чтобы преподаватель был бы лучшим инструментом, чем Turgines Machines. Оказывается, оказывается, что он может быть реализован в сборке - таким образом, Lisp, язык программирования родился.
Но я не думаю, что это действительно то, что вы ищете, поскольку вычислительная модель, которую Lisp описывает, не имеет петлей: вместо этого используется рекурсия. Синтаксис получает от алгебры, где брекеты обозначают оценку - это и заменитель - результат. Действительно, модель вычислений Лисски в основном замена - какая алгебра по существу.
Действительно, большинство функциональных языков, таких как Lisp, Haskell и Erlang, получены из математики. Haskell на самом деле является результатом доказательства того, что лямбда-исчисление может использоваться для реализации систем типа. Таким образом, Haskell, как Лисс родился из чистой математики. Но опять же, синтаксис не то, к чему вы, вероятно, привыкли.
Вы, безусловно, можете объяснить синтаксис Lisp и Haskell к математикам, и они будут относиться к нему как «игра». Языковые конструкции, такие как петли, рекурсия и условные условия, могут быть доказаны из правил игры, а не вслепую, как на других языках. Это приведет вас к сферам комбинационеры, другой отделения математики. Действительно, в комбинатине, даже концепция чисел может быть извлечена из правил игры, а не в родной части языка (церковные цифры Google).
Так что посмотрите на Lisp / схему, Erlang и Haskell, если хотите. Erlang особенно имеет синтаксис рядом с тем, что вы хотите:
add(a,b) -> a + b
, но моя рекомендация - писать в C-похожий псевдокод. Это своего рода самый низкий общий знаменатель в языках программирования. Имеет синтаксис, который довольно легко понять и чистить. И функциональный синтаксис даже вытекает из функций в математике. Помните f (x) ?
Как плюс математики используются для написания C, статистики используются для записи C (хотя обычно они предпочитают R), используются физики для записи C, программисты используются по крайней мере, глядя на C (я знаю несколько, кто никогда не трогал в).
На самом деле, царапать это. Вы упоминаете, что ваша целевая аудитория статистики. Написать в R
APL ? Единственная проблема в том, что немногие люди могут прочитать его.
Версия генератора нерекурсивного решения @ unutbu, запрошенная @ Andrew в комментарии:
def genflat(l, ltypes=collections.Sequence):
l = list(l)
i = 0
while i < len(l):
while isinstance(l[i], ltypes):
if not l[i]:
l.pop(i)
i -= 1
break
else:
l[i:i + 1] = l[i]
yield l[i]
i += 1
немного упрощенная версия этого генератора:
def genflat(l, ltypes=collections.Sequence):
l = list(l)
while l:
while l and isinstance(l[0], ltypes):
l[0:1] = l[0]
if l: yield l.pop(0)
Simple Regex:
\w +
Это соответствует последовательности символов «word». Это почти то, что вы хотите.
Это несколько более точно:
\w (? < !\d) [\w '-] *
Он соответствует любому количеству символов слова, гарантируя, что первый символ не является цифрой.
Вот мои совпадения:
1 ЛОЛОЛОЛ
2 ВЫ
3 БЫЛО
4 PWN3D
5 einszwei
6 drei
Это больше похоже на это.
EDIT:
Причина отрицательного обзора заключается в том, что некоторые ароматизаторы regex поддерживают символы Юникода. При использовании [a-zA-Z] будет пропущено несколько желательных символов «слова». Разрешение \w и запрет \d включает в себя все символы Юникода, которые могли бы начать слово в любом блоке текста.
EDIT 2:
Я нашел более сжатый способ получить эффект отрицательного lookbehind: Double negative character class с единственным отрицательным исключением.
[^\W\d] [\w '-] * (? < =\w)
Это то же самое, что и выше, за исключением того, что это также гарантирует, что слово заканчивается символом слова. И, наконец, есть:
[^\W\d] (\w | [- '] {1,2} (? =\w)) *
Обеспечение наличия не более двух несловосочетаний в строке. Она совпадает со словами, но не со словами, что имеет смысл. Если вы хотите, чтобы он соответствовал «word--up», но не «word---up», вы можете изменить 2 на 3 .
Символ для общих контуров не существует; обычно используется оператор суммирования . «if» представляется с помощью последствий , и для «добавления кортежа в список» используется объединение .
Однако , в целом, немного многословности не обязательно является плохой вещью - иногда, особенно для сложных алгоритмов, лучше прописать ее на простом английском языке, используя примеры и диаграммы. Это дважды верно для некодеров.
Подумайте об этом: когда вы читаете математический учебник по алгоритму Евклида для GCD, или сито Эратосфена, как это написано? Обычно сам алгоритм находится в прозе, в то время как доказательством алгоритма является то, где лежат математические символы.
Не делайте этого. Вы отклоняетесь от того, что люди ожидают увидеть, когда они читают газету о алгоритмах. Вы должны следовать ожидаемым практикам; Ваши идеи с большей вероятностью привлеките внимание, что они заслуживают. Когда в Риме делают как римляне.
Код форматирования (или псевдокод, как это может быть) в латексированной бумаге очень легко. См., Например, код форматирования в LaTex .