алгоритм для нахождения краев с помощью вершин (2D и 3D) в сетке
У меня есть сетка, с определенными типами элементов (например, треугольный, tetra). Для каждого элемента я знаю все его вершины, т.е. треугольный 2D элемент будет иметь 3 вершины v1, v2 и v3, x которого, y, z провода известны.
Вопрос 1
Я ищу алгоритм, который возвратит все края... в этом случае:
край (v1, v2), край (v1, v3), край (v2, v3). На основе того, сколько вершин каждый элемент имеет, алгоритм должен эффективно определить края.
Вопрос 2
Я использую C++, таким образом, каков будет самый эффективный способ хранить информацию о краях, возвращенных вышеупомянутым алгоритмом? Пример, все, чем я интересуюсь, является кортежем (v1, v2), что я хочу использовать для некоторого вычисления и затем забыть об этом.
Спасибо
3 ответа
Вы можете использовать половинную структуру данных.
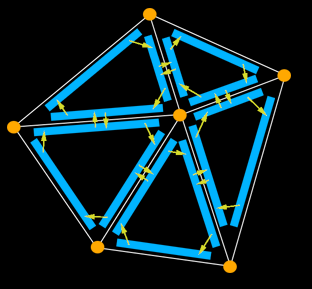
Обычно ваша сетка также имеет список ребер, и есть одна структура ребер на пару вершин в каждом направлении. Это означает, что если у вас есть вершины A и B, то где-то хранятся две структуры ребер: одна для A-> B и одна для B-> A. Каждое ребро имеет 3 указателя, один из которых называется предыдущим, второй - следующим, а третий - близнецом. При переходе к следующему и предыдущему указателям вы перемещаетесь по краям треугольника или многоугольника в сетке. Вызов двойника приведет вас к соседнему краю в соседнем многоугольнике или треугольнике. (Посмотрите на стрелки на картинке) Это самая полезная и подробная структура данных ребер, о которой я знаю. Я использовал его для сглаживания сеток, создавая новые края и обновляя указатели. Кстати, каждое ребро также должно указывать на вершину, чтобы знать, где оно находится в пространстве.
У меня нет алгоритмов для вас, но я могу сказать, где искать.
"Point Set Triangulation" - это то, что вы ищете.
Вот несколько библиотек с открытым исходным кодом, которые сделают это за вас (изучите код для алгоритмов):
- Классы Triangulation_2 и Triangulation_3 CGAL.
- Triangle (только 2D) от Jonathan Richard Shewchuk
- Fast Polygon Triangulation от Atul Narkhede и Dinesh Manocha
На самом деле ваш вопрос состоит из трех частей, а не двух:
- Какие структуры данных следует использовать для представления сетки?
- Какой алгоритм мне следует использовать для извлечения ребер из структур данных сетки?
- Как должен быть представлен результирующий набор ребер?
Вы должны задать дополнительные вопросы, чтобы найти подходящие ответы.
Какие структуры данных следует использовать для представления сетки?
Какие типы элементов вам нужно обрабатывать?
Если вам нужно обрабатывать только многоугольники (замкнутые циклы) и симплициальные элементы (каждый узел соединен со всеми другими узла в элементе, таком как тетраэдр), то достаточно упорядоченного списка узлов, потому что из списка узлов могут подразумеваться ребра. Если, с другой стороны, вам нужно работать с такими типами элементов, как шестигранники, призмы или общие многогранники, вам потребуется дополнительная информация о топологии элемента. Часто бывает достаточно простого массива отображений ребер. Это просто массив [] [2] индексов в списке узлов элемента, который сообщает вам, как соединить точки для данного типа элемента.
Полурабельная структура, описанная Крисом, является хорошим выбором только для 2D. В 3D может быть произвольное количество элементов, прикрепленных к каждому краю, а не только два. Существует трехмерное расширение представления полуребра, которое, как мне кажется, называется структурой вертушки.
Если вам нужно поддерживать произвольные типы элементов, я предпочитаю более полную структуру данных для представления топологии элементов. Обычный вариант - использовать ребра и совместные ребра.Существует структура ребер для каждой пары соединенных узлов и со-ребро для каждого использования этого ребра в элементе. Это похоже на подход вертушки, но немного более явный.
Какой алгоритм мне следует использовать для извлечения ребер из элементов?
Насколько важны скорость или память? Должен ли результат включать каждое ребро один раз для каждого элемента или только один раз, независимо от того, сколько элементов его используют? Имеет ли значение порядок ребер в результате? Имеет ли значение порядок узлов каждого ребра?
Довольно сложно придумать алгоритм для произвольных типов элементов, который будет посещать каждое ребро только один раз. Чтобы гарантировать, что каждое ребро появляется только один раз, вы можете либо отфильтровать результат, либо проявить немного хакерства и оставить бит «посещенных» на каждом ребре, чтобы гарантировать, что вы не вставите его в результат дважды.
Как мне представить результаты?
Какое значение имеет то, как я буду использовать результат?
Если вы собираетесь использовать результат в вычислениях, требующих большого объема вычислений, большой массив координат может быть лучшим вариантом. Вы не хотите повторно получать координаты узла снова и снова во время вычислений. Однако, если вы фильтруете результаты, чтобы удалить повторяющиеся ребра, сравнение координат (6 двойных значений для пары узлов) не подходит. Если вы выполняете фильтрацию, сначала сгенерируйте список указателей на структуры ребер, затем отфильтруйте дубликаты, а затем , затем сгенерируйте свой список координат. Вы можете использовать этот подход и с парами узлов, но тогда вам придется фильтровать оба возможных порядка узлов на ребро, удваивая количество времени, необходимое для фильтрации.
Список крайних указателей также можно использовать, если память важнее производительности. Однако вместо преобразования вашего списка ребер в список координат,вы ищите координаты во время расчета. Получение координат узла происходит медленнее, но вы избегаете создания огромного списка координат - вы сохраняете один указатель на каждую грань вместо 6 двойных единиц на каждую грань.
Многие сеточные приложения хранят все координаты в большом глобальном массиве, причем каждый узел имеет индекс в массиве. В этом случае вместо преобразования списка ребер в массив координат преобразуйте его в список индексов в массив глобальных координат. Производительность не должна сильно отличаться от локального массива координат, но без накладных расходов на память и заполнение.