Выражение целого числа как серия множителей
Вы не должны обновлять в действии редактирования, это действие только для отображения формы. Удалите строку
@product.update(product_parameters)
из действия редактирования.
product_parameters должно быть с обязательной деталью для корректного обновления продукта
13 ответов
Update
I couldn't resist trying to come up with my own solution for the first question even though it doesn't do compression. Here is a Python solution using a third party factorization algorithm called pyecm.
This solution is probably several magnitudes more efficient than Yevgeny's one. Computations take seconds instead of hours or maybe even weeks/years for reasonable values of y. For x = 2^32-1 and y = 256, it took 1.68 seconds on my core duo 1.2 ghz.
>>> import time
>>> def test():
... before = time.time()
... print factor(2**32-1, 256)
... print time.time()-before
...
>>> test()
[254, 232, 215, 113, 3, 15]
1.68499994278
>>> 254*232*215*113*3+15
4294967295L
And here is the code:
def factor(x, y):
# y should be smaller than x. If x=y then {y, 1, 0} is the best solution
assert(x > y)
best_output = []
# try all possible remainders from 0 to y
for remainder in xrange(y+1):
output = []
composite = x - remainder
factors = getFactors(composite)
# check if any factor is larger than y
bad_remainder = False
for n in factors.iterkeys():
if n > y:
bad_remainder = True
break
if bad_remainder: continue
# make the best factors
while True:
results = largestFactors(factors, y)
if results == None: break
output += [results[0]]
factors = results[1]
# store the best output
output = output + [remainder]
if len(best_output) == 0 or len(output) < len(best_output):
best_output = output
return best_output
# Heuristic
# The bigger the number the better. 8 is more compact than 2,2,2 etc...
# Find the most factors you can have below or equal to y
# output the number and unused factors that can be reinserted in this function
def largestFactors(factors, y):
assert(y > 1)
# iterate from y to 2 and see if the factors are present.
for i in xrange(y, 1, -1):
try_another_number = False
factors_below_y = getFactors(i)
for number, copies in factors_below_y.iteritems():
if number in factors:
if factors[number] < copies:
try_another_number = True
continue # not enough factors
else:
try_another_number = True
continue # a factor is not present
# Do we want to try another number, or was a solution found?
if try_another_number == True:
continue
else:
output = 1
for number, copies in factors_below_y.items():
remaining = factors[number] - copies
if remaining > 0:
factors[number] = remaining
else:
del factors[number]
output *= number ** copies
return (output, factors)
return None # failed
# Find prime factors. You can use any formula you want for this.
# I am using elliptic curve factorization from http://sourceforge.net/projects/pyecm
import pyecm, collections, copy
getFactors_cache = {}
def getFactors(n):
assert(n != 0)
# attempt to retrieve from cache. Returns a copy
try:
return copy.copy(getFactors_cache[n])
except KeyError:
pass
output = collections.defaultdict(int)
for factor in pyecm.factors(n, False, True, 10, 1):
output[factor] += 1
# cache result
getFactors_cache[n] = output
return copy.copy(output)
Answer to first question
You say you want compression of numbers, but from your examples, those sequences are longer than the undecomposed numbers. It is not possible to compress these numbers without more details to the system you left out (probability of sequences/is there a programmable client?). Could you elaborate more?
Here is a mathematical explanation as to why current answers to the first part of your problem will never solve your second problem. It has nothing to do with the knapsack problem.
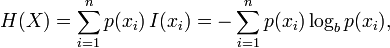
This is Shannon's entropy algorithm. It tells you the theoretical minimum amount of bits you need to represent a sequence {X0, X1, X2, ..., Xn-1, Xn} where p(Xi) is the probability of seeing token Xi.
Let's say that X0 to Xn is the span of 0 to 4294967295 (the range of an integer). From what you have described, each number is as likely as another to appear. Therefore the probability of each element is 1/4294967296.
When we plug it into Shannon's algorithm, it will tell us what the minimum number of bits are required to represent the stream.
import math
def entropy():
num = 2**32
probability = 1./num
return -(num) * probability * math.log(probability, 2)
# the (num) * probability cancels out
The entropy unsurprisingly is 32. We require 32 bits to represent an integer where each number is equally likely. The only way to reduce this number, is to increase the probability of some numbers, and decrease the probability of others. You should explain the stream in more detail.
Answer to second question
The right way to do this is to use base64, when communicating with HTTP. Apparently Java does not have this in the standard library, but I found a link to a free implementation:
http://iharder.sourceforge.net/current/java/base64/
Here is the "pseudo-code" which works perfectly in Python and should not be difficult to convert to Java (my Java is rusty):
def longTo64(num):
mapping = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_"
output = ""
# special case for 0
if num == 0:
return mapping[0]
while num != 0:
output = mapping[num % 64] + output
num /= 64
return output
If you have control over your web server and web client, and can parse the entire HTTP requests without problem, you can upgrade to base85. According to wikipedia, url encoding allows for up to 85 characters. Otherwise, you may need to remove a few characters from the mapping.
Here is another code example in Python
def longTo85(num):
mapping = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_.~!*'();:@&=+$,/?%#[]"
output = ""
base = len(mapping)
# special case for 0
if num == 0:
return mapping[0]
while num != 0:
output = mapping[num % base] + output
num /= base
return output
And here is the inverse operation:
def stringToLong(string):
mapping = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_.~!*'();:@&=+$,/?%#[]"
output = 0
base = len(mapping)
place = 0
# check each digit from the lowest place
for digit in reversed(string):
# find the number the mapping of symbol to number, then multiply by base^place
output += mapping.find(digit) * (base ** place)
place += 1
return output
Here is a graph of Shannon's algorithm in different bases.

Как видите, чем выше основание, тем меньше символов необходимо для представления числа. На base64 требуется ~ 11 символов для представления long. На base85 он становится ~ 10 символов.
Правка после окончательного объяснения:
Я думаю, что base64 - лучшее решение, так как есть стандартные функции, которые имеют дело с ним, и варианты этой идеи не дают большого улучшения. На этот вопрос ответили более подробно другие здесь.
Что касается исходного вопроса, хотя код работает, он не гарантированно запустится в любое разумное время, на что ответил LFSR Consulting, а также прокомментировал этот вопрос. 1288] Оригинальный ответ:
Вы имеете в виду что-то подобное?
Редактировать - исправлено после комментария.
shortest_output = {}
foreach (int R = 0; R <= X; R++) {
// iteration over possible remainders
// check if the rest of X can be decomposed into multipliers
newX = X - R;
output = {};
while (newX > Y) {
int i;
for (i = Y; i > 1; i--) {
if ( newX % i == 0) { // found a divider
output.append(i);
newX = newX /i;
break;
}
}
if (i == 1) { // no dividers <= Y
break;
}
}
if (newX != 1) {
// couldn't find dividers with no remainder
output.clear();
}
else {
output.append(R);
if (output.length() < shortest_output.length()) {
shortest_output = output;
}
}
}
Разве это не модуль?
Пусть / будет целочисленным делением (целые числа), а % будет по модулю.
int result[3];
result[0] = y;
result[1] = x / y;
result[2] = x % y;
Просто установите x: = x / n, где n - это наибольшее число , которое меньше как x, так и y. Когда вы заканчиваете с x <= y, это ваш последний номер в последовательности.
Как и в моем комментарии выше, я не уверен, что точно понимаю вопрос. Но при условии целых чисел (n и заданного y), это должно работать в случаях, которые вы указали:
multipliers[0] = n / y;
multipliers[1] = y;
addedNumber = n % y;
Обновлено после полной истории
Base64, скорее всего, ваш лучший вариант. Если вам нужно индивидуальное решение, вы можете попробовать внедрить систему Base 65+. Просто помните, что то, что 10000 можно записать как «10 ^ 4», не означает, что все можно записать как 10 ^ n, где n - целое число. Различные базовые системы - это самый простой способ написания чисел, и чем выше база, тем меньше цифр требуется число. Плюс большинство библиотек каркасов содержат алгоритмы для кодирования Base64. (Какой язык вы используете?).
Одним из способов дальнейшей упаковки URL-адресов является тот, который вы упомянули, но в Base64.
int[] IDs;
IDs.sort() // So IDs[i] is always smaller or equal to IDs[i-1].
string url = Base64Encode(IDs[0]);
for (int i = 1; i < IDs.length; i++) {
url += "," + Base64Encode(IDs[i-1] - IDs[i]);
}
Обратите внимание, что вам нужен какой-то разделитель, поскольку начальный идентификатор может быть сколь угодно большим, а разница между двумя Идентификаторы МОГУТ быть больше 63, и в этом случае одной цифры Base64 недостаточно.
Обновлено
Просто повторяю, что проблема неразрешима. Для Y = 64 вы не можете написать 87681 в множителях + остаток, где каждое из них меньше 64. Другими словами, вы не можете написать ни одно из чисел 87617..87681 с множителями ниже 64. Каждое из этих чисел имеет элементарный термин свыше 64. 87616 можно записать в элементарных терминах ниже 64, но тогда вам понадобятся эти + 65, и поэтому остаток будет больше 64.
Так что, если это был просто головоломка, это неразрешимо. Была ли какая-то практическая цель для этого, которая могла бы быть достигнута каким-то иным способом, кроме использования умножения и остатка?
И да, это действительно должен быть комментарий, но я потерял способность комментировать в какой-то момент. : p
Я полагаю, что наиболее близким решением является решение Евгения. Евгения так же легко продлить s решение удалить предел для остатка, и в этом случае он сможет найти решение, где множители меньше Y, а остаток как можно меньше, даже если больше Y.
Старый ответ:
Если вы ограничиваете что каждое число в массиве должно быть ниже y, тогда для этого нет решения. Учитывая достаточно большой x и достаточно маленький y, вы окажетесь в невозможной ситуации. Как пример с y, равным 2, x из 12, вы получите 2 * 2 * 2 + 4, так как 2 * 2 * 2 * 2 будет 16. Даже если вы допустите отрицательные числа с abs (n) ниже y, это не не работает так, как вам нужно 2 * 2 * 2 * 2 - 4 в приведенном выше примере.
И я думаю, что проблема в NP-Complete, даже если вы ограничиваете проблему входами, о которых известно, что у них есть ответ, где последний срок меньше, чем у. Это звучит очень похоже на [проблему с рюкзаком] [1]. Конечно, я могу ошибаться.
Редактировать:
Без более точного описания проблемы трудно решить проблему, но один вариант может работать следующим образом:
- set current = x
- Break текущий к его терминам
- Если один из терминов больше, чем y, текущее число не может быть описано в терминах, превышающих y. Уменьшите одно с текущего и повторите с 2.
- Текущее число может быть выражено в терминах, меньших чем y.
- Вычислить остаток
- Объедините столько терминов, сколько возможно.
(Евгений Доктор имеет больше совести ( и работает) реализация этого, чтобы избежать путаницы, я пропустил реализацию.)
- set current = x
- Отключить ток до его условий
- Если один из членов больше y, текущее число не может быть описано в терминах, превышающих y. Уменьшите одно с текущего и повторите с 2.
- Текущее число может быть выражено в терминах, меньших чем y.
- Вычислить остаток
- Объедините столько терминов, сколько возможно.
(Евгений Доктор имеет больше совести ( и работает) реализация этого, чтобы избежать путаницы, я пропустил реализацию.)
- set current = x
- Отключить ток до его условий
- Если один из членов больше y, текущее число не может быть описано в терминах, превышающих y. Уменьшите одно с текущего и повторите с 2.
- Текущее число может быть выражено в терминах, меньших чем y.
- Вычислить остаток
- Объедините столько терминов, сколько возможно.
(Евгений Доктор имеет больше совести ( и работает) реализация этого, чтобы избежать путаницы, я пропустил реализацию.)
Звучит так, как будто вы хотите сжать случайные данные - это невозможно по теоретико-информационным причинам. (См. http://www.faqs.org/faqs/compression-faq/part1/preamble.html вопрос 9.) Используйте Base64 для составных двоичных представлений ваших чисел и покончите с этим.
Обновление: Я не получил все, поэтому переписал все это в стиле Java. Я не думал о случае простых чисел, который больше делителя. Это исправлено сейчас. Я оставляю исходный код, чтобы понять идею.
Обновление 2: Теперь я рассматриваю случай большого простого числа другим способом. Таким образом, результат получается в любом случае.
public final class PrimeNumberException extends Exception {
private final long primeNumber;
public PrimeNumberException(long x) {
primeNumber = x;
}
public long getPrimeNumber() {
return primeNumber;
}
}
public static Long[] decompose(long x, long y) {
try {
final ArrayList<Long> operands = new ArrayList<Long>(1000);
final long rest = x % y;
// Extract the rest so the reminder is divisible by y
final long newX = x - rest;
// Go into recursion, actually it's a tail recursion
recDivide(newX, y, operands);
} catch (PrimeNumberException e) {
// return new Long[0];
// or do whatever you like, for example
operands.add(e.getPrimeNumber());
} finally {
// Add the reminder to the array
operands.add(rest);
return operands.toArray(new Long[operands.size()]);
}
}
// The recursive method
private static void recDivide(long x, long y, ArrayList<Long> operands)
throws PrimeNumberException {
while ((x > y) && (y != 1)) {
if (x % y == 0) {
final long rest = x / y;
// Since y is a divisor add it to the list of operands
operands.add(y);
if (rest <= y) {
// the rest is smaller than y, we're finished
operands.add(rest);
}
// go in recursion
x = rest;
} else {
// if the value x isn't divisible by y decrement y so you'll find a
// divisor eventually
if (--y == 1) {
throw new PrimeNumberException(x);
}
}
}
}
Оригинал: Вот некоторый рекурсивный код, который я придумал. Я бы предпочел кодировать его на каком-то функциональном языке, но это было необходимо в Java. Я не удосужился преобразовать числа в целое, но это не должно быть так сложно (да, я ленивый;)
public static Long[] decompose(long x, long y) {
final ArrayList<Long> operands = new ArrayList<Long>();
final long rest = x % y;
// Extract the rest so the reminder is divisible by y
final long newX = x - rest;
// Go into recursion, actually it's a tail recursion
recDivide(newX, y, operands);
// Add the reminder to the array
operands.add(rest);
return operands.toArray(new Long[operands.size()]);
}
// The recursive method
private static void recDivide(long newX, long y, ArrayList<Long> operands) {
long x = newX;
if (x % y == 0) {
final long rest = x / y;
// Since y is a divisor add it to the list of operands
operands.add(y);
if (rest <= y) {
// the rest is smaller than y, we're finished
operands.add(rest);
} else {
// the rest can still be divided, go one level deeper in recursion
recDivide(rest, y, operands);
}
} else {
// if the value x isn't divisible by y decrement y so you'll find a divisor
// eventually
recDivide(x, y-1, operands);
}
}
Проблема, которую вы пытаетесь решить (вы имеете дело с подмножеством проблемы, если у вас есть ограничение y ), называется Integer Факторизация , и это не может быть эффективно выполнено с помощью любого известного алгоритма:
В теории чисел, целочисленная факторизация - это разбиение составного числа на более мелкие нетривиальные делители, которые при умножении вместе равны исходному целому числу.
] Эта проблема делает возможным использование ряда криптографических функций (а именно RSA, который использует 128-битные ключи - длина составляет половину от этого.) На вики-странице есть несколько полезных ресурсов, которые должны направить вас в правильном направлении с вашей проблемой.
Итак, ваш тизер мозга - это действительно дразнилка мозга ... и если вы решите его эффективно, мы сможем поднять ваши математические навыки до уровня выше среднего!
Исходный метод, который вы выбрали (a * b + c * d + e) , было бы очень трудно найти оптимальные решения просто из-за большого поиска пространство возможностей. Вы можете факторизовать число, но это то, что "+ e" усложняет ситуацию, так как вам нужно факторизовать не просто это число, а довольно много сразу под ним.
Два метода для Сразу вспоминается пружина сжатия, которая дает гораздо более чем 10-процентную экономию пространства от числового представления.
64-разрядное число варьируется от (без знака):
0 to
18,446,744,073,709,551,616
или (со знаком):
-9,223,372,036,854,775,808 to
9,223,372,036,854,775,807
В обоих случаях вам нужно уменьшить количество взятых 20 символов (без запятых) до значения немного меньшего.
Во-первых, это просто BCD-ify число, которое кодирует base64 (на самом деле это слегка измененное base64, поскольку "/" не будет кошерным в URL-адресе - вы должны использовать один из допустимых символов, таких как as "_" ).
Преобразование его в BCD сохранит две цифры (или знак и цифру) в одном байте, что даст вам сокращение пространства на 50% (10 байтов). Кодирование с помощью base 64 (который превращает каждые 3 байта в 4 символа base64) превратит первые 9 байтов в 12 символов, а этот десятый байт - в 2 символа, всего 14 символов - это экономия 30%.
лучший способ - просто кодировать base64 двоичным представлением. Это лучше, потому что BCD имеет небольшое количество потерь (каждая цифра требует только 3,32 бит для хранения [log 2 10], но BCD использует 4).
Работая с двоичным представлением, нам нужно только base64 кодировать 64-битное число (8 байт). Это требует 8 символов для первых 6 байтов и 3 символа для последних 2 байтов. Это 11 символов base64 для экономии 45%.
Если вы хотите максимальное сжатие , для кодирования URL доступно 73 символа:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz
0123456789$-_.+!*'(),
, так что технически вы можете кодировать base-73, который, из грубых вычислений, все равно будет занимать 11 символов, но с более сложным кодом, который, на мой взгляд, не стоит.
Конечно, это максимальное сжатие из-за максимальных значений. На другом конце шкалы (1 цифра) это кодирование фактически приводит к большему числу данных (расширение, а не сжатие). Вы можете видеть, что улучшения начинаются только для чисел свыше 999, где 4 цифры можно превратить в 3 символа base64:
Range (bytes) Chars Base64 chars Compression ratio
------------- ----- ------------ -----------------
< 10 (1) 1 2 -100%
< 100 (1) 2 2 0%
< 1000 (2) 3 3 0%
< 10^4 (2) 4 3 25%
< 10^5 (3) 5 4 20%
< 10^6 (3) 6 4 33%
< 10^7 (3) 7 4 42%
< 10^8 (4) 8 6 25%
< 10^9 (4) 9 6 33%
< 10^10 (5) 10 7 30%
< 10^11 (5) 11 7 36%
< 10^12 (5) 12 7 41%
< 10^13 (6) 13 8 38%
< 10^14 (6) 14 8 42%
< 10^15 (7) 15 10 33%
< 10^16 (7) 16 10 37%
< 10^17 (8) 17 11 35%
< 10^18 (8) 18 11 38%
< 10^19 (8) 19 11 42%
< 2^64 (8) 20 11 45%
Are you married to using Java? Python has an entire package dedicated just for this exact purpose. It'll even sanitize the encoding for you to be URL-safe.
Native Python solution
The standard module I'm recommending is base64, which converts arbitrary stings of chars into sanitized base64 format. You can use it in conjunction with the pickle module, which handles conversion from lists of longs (actually arbitrary size) to a compressed string representation.
The following code should work on any vanilla installation of Python:
import base64
import pickle
# get some long list of numbers
a = (854183415,1270335149,228790978,1610119503,1785730631,2084495271,
1180819741,1200564070,1594464081,1312769708,491733762,243961400,
655643948,1950847733,492757139,1373886707,336679529,591953597,
2007045617,1653638786)
# this gets you the url-safe string
str64 = base64.urlsafe_b64encode(pickle.dumps(a,-1))
print str64
>>> gAIoSvfN6TJKrca3S0rCEqMNSk95-F9KRxZwakqn3z58Sh3hYUZKZiePR0pRlwlfSqxGP05KAkNPHUo4jooOSixVFCdK9ZJHdEqT4F4dSvPY41FKaVIRFEq9fkgjSvEVoXdKgoaQYnRxAC4=
# this unwinds it
a64 = pickle.loads(base64.urlsafe_b64decode(str64))
print a64
>>> (854183415, 1270335149, 228790978, 1610119503, 1785730631, 2084495271, 1180819741, 1200564070, 1594464081, 1312769708, 491733762, 243961400, 655643948, 1950847733, 492757139, 1373886707, 336679529, 591953597, 2007045617, 1653638786)
Hope that helps. Using Python is probably the closest you'll get from a 1-line solution.
О.П. Написал:
Первоначально моей целью было придумать конкретный способ упаковать 1..n большой целые числа (иначе длинные) вместе, так что их строковое представление заметно короче, чем написание фактического число. Думайте кратно десяти, 10 ^ 6 и 1 000 000 одинаковы, однако длина представления в символов нет.
Я уже шел по этому пути раньше, и как бы весело ни было выучить всю математику, чтобы сэкономить ваше время, я просто укажу на: http: //en.wikipedia. org / wiki / Kolmogorov_complexity
В двух словах некоторые строки могут быть легко сжаты путем изменения вашей записи:
10^9 (4 characters) = 1000000000 (10 characters)
Другие не могут:
7829203478 = some random number...
Это большое большое упрощение статьи, на которую я ссылался выше, поэтому я рекомендую вам прочитайте его вместо того, чтобы принимать мое объяснение за чистую монету.
Редактировать: Если вы пытаетесь создать RESTful URL для некоторого набора уникальных данных, почему бы вам не использовать хеш, такой как MD5? Затем включите хеш как часть URL, затем ищите данные на основе хеша. Или я что-то упускаю очевидное?
По сравнению с исходным запросом алгоритма: существует ли ограничение на размер последнего числа (помимо этого оно должно храниться в 32-битном целом)? (Первоначальный запрос - это все, что я могу решить. Lol.)
Тот, который создает самый короткий список:
bool negative=(n<1)?true:false;
int j=n%y;
if(n==0 || n==1)
{
list.append(n);
return;
}
while((long64)(n-j*y)>MAX_INT && y>1) //R has to be stored in int32
{
y--;
j=n%y;
}
if(y<=1)
fail //Number has no suitable candidate factors. This shouldn't happen
int i=0;
for(;i<j;i++)
{
list.append(y);
}
list.append(n-y*j);
if(negative)
list[0]*=-1;
return;
Немного упрощен по сравнению с большинством ответов, которые были даны до сих пор, но он достигает желаемой функциональности исходного поста. ... Это немного грязно, но, надеюсь, полезно :)