Отсортированное различие в списке
Спасибо всем, кто дал некоторое представление ...
Оказалось, что это был внешний файл javascript, содержащий блок try / catch в виде:
try {
// code
}
catch {
// code
}
При изменении на:
try {
// code
}
catch(err) {
// code
}
... после внесения изменений все тесты пройдены !!
6 ответов
Ро Спирмена
Думаю, вам нужен коэффициент ранговой корреляции Спирмена . Используя векторы индекса [rank] для двух сортировок (идеальный A и приблизительный B ), вы вычисляете ранговую корреляцию rho в диапазоне от -1 (совершенно разные ) до 1 (точно так же):
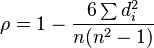
где d (i) - разница в рангах для каждого символа между A и B
Вы можете определить вашу меру ошибки как расстояние D: = (1 -rho) / 2 .
Я бы определил самый большой правильно упорядоченный подмножество.
+-------------> I
| +--------->
| |
A -> B -> D -----> E -> G -> H --|--> J
| ^ | | ^
| | | | |
+------> C ---+ +-----------> F ---+
В вашем примере 7 из 10, поэтому алгоритм оценивает 0,7. Остальные наборы имеют длину 6. Оценка правильного порядка 1.0, обратный порядок 1 / n.
Я предполагаю, что это связано с количеством инверсий. x + y указывает x <= y (правильный порядок), а x - y указывает x> y (неправильный порядок).
A + B + D - C + E + G + H - F + J - I
Получаем практически тот же результат - 6 из 9 правильных рифлений 0,667. Снова исправьте порядок оценок 1,0 и обратный порядок 0,0, и это может быть намного проще вычислить.
Вы ищете алгоритм, который вычисляет разницу на основе массива, отсортированного с помощью A, и массива, отсортированного с использованием B в качестве входных данных? Или вы ищете универсальный метод определения в среднем отклонения от массива при сортировке с помощью B?
Если первый, то я предлагаю что-то столь же простое, как расстояние, на котором каждый элемент находится от того места, где он должен быть (среднее было бы лучше, чем сумма, чтобы удалить длину массива как проблему)
Если второе, то я думаю, что мне нужно больше узнать об этих алгоритмах.
Трудно дать хороший общий ответ, потому что правильное решение для вас будет зависеть от вашего приложения.
Один из моих любимых вариантов - это просто количество упорядоченных пар элементов, делится на общее количество пар. Это приятная, простая и легко вычисляемая метрика, которая просто говорит вам, сколько существует ошибок. Но он не пытается количественно оценить величину этих ошибок.
double sortQuality = 1;
if (array.length > 1) {
int inOrderPairCount = 0;
for (int i = 1; i < array.length; i++) {
if (array[i] >= array[i - 1]) ++inOrderPairCount;
}
sortQuality = (double) inOrderPairCount / (array.length - 1);
}
Расчет RMS-ошибки может быть одним из многих возможных методов. Вот небольшой код на Python.
def calc_error(out_A,out_B):
# in <= input
# out_A <= output of algorithm A
# out_B <= output of algorithm B
rms_error = 0
for i in range(len(out_A)):
# Take square of differences and add
rms_error += (out_A[i]-out_B[i])**2
return rms_error**0.5 # Take square root
>>> calc_error([1,2,3,4,5,6],[1,2,3,4,5,6])
0.0
>>> calc_error([1,2,3,4,5,6],[1,2,4,3,5,6]) # 4,3 swapped
1.414
>>> calc_error([1,2,3,4,5,6],[1,2,4,6,3,5]) # 3,4,5,6 randomized
2.44
ПРИМЕЧАНИЕ: Извлечение квадратного корня не обязательно, но возведение квадратов - это просто разница в сумме равной нулю. Я думаю, что функция calc_error дает приблизительное количество неправильно размещенных пар, но у меня нет никаких инструментов программирования, поэтому: (.
Взгляните на этот вопрос.
вы можете попробовать что-нибудь, связанное с расстоянием Хэмминга