Как лучше создать горизонтальные стеки с несколькими переменными от ggplot2?
Я часто должен делать сложенный barplots для сравнения переменных, и потому что я делаю всю свою статистику в R, я предпочитаю делать всю свою графику в R с ggplot2. Я хотел бы изучить, как сделать две вещи:
Во-первых, я хотел бы смочь добавить надлежащие метки процента для каждый переменные а не метки количеством. Количества сбивали бы с толку, который является, почему я вынимаю подписи оси полностью.
Во-вторых, должен быть более простой способ реорганизовать мои данные, чтобы заставить это произойти. На вид вещи кажется, что я должен смочь сделать исходно в ggplot2 с plyR, но документация для plyR не является очень четкой (и я прочитал и книгу ggplot2 и plyR документацию онлайн.
Мой лучший график похож на это, код для создания его следует:
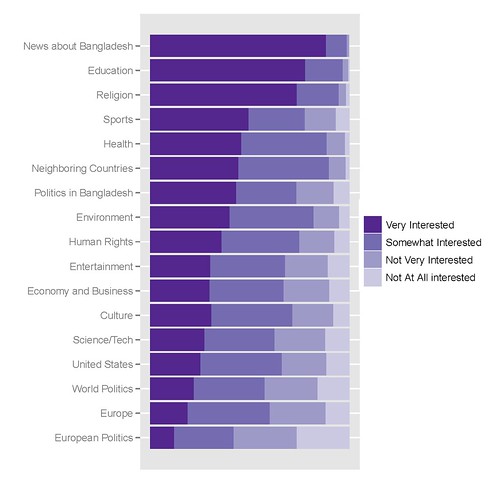
R кодируют, я использую для получения, это следующее:
library(epicalc)
### recode the variables to factors ###
recode(c(int_newcoun, int_newneigh, int_neweur, int_newusa, int_neweco, int_newit, int_newen, int_newsp, int_newhr, int_newlit, int_newent, int_newrel, int_newhth, int_bapo, int_wopo, int_eupo, int_educ), c(1,2,3,4,5,6,7,8,9, NA),
c('Very Interested','Somewhat Interested','Not Very Interested','Not At All interested',NA,NA,NA,NA,NA,NA))
### Combine recoded variables to a common vector
Interest1<-c(int_newcoun, int_newneigh, int_neweur, int_newusa, int_neweco, int_newit, int_newen, int_newsp, int_newhr, int_newlit, int_newent, int_newrel, int_newhth, int_bapo, int_wopo, int_eupo, int_educ)
### Create a second vector to label the first vector by original variable ###
a1<-rep("News about Bangladesh", length(int_newcoun))
a2<-rep("Neighboring Countries", length(int_newneigh))
[...]
a17<-rep("Education", length(int_educ))
Interest2<-c(a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, a16, a17)
### Create a Weighting vector of the proper length ###
Interest.weight<-rep(weight, 17)
### Make and save a new data frame from the three vectors ###
Interest.df<-cbind(Interest1, Interest2, Interest.weight)
Interest.df<-as.data.frame(Interest.df)
write.csv(Interest.df, 'C:\\Documents and Settings\\[name]\\Desktop\\Sweave\\InterestBangladesh.csv')
### Sort the factor levels to display properly ###
Interest.df$Interest1<-relevel(Interest$Interest1, ref='Not Very Interested')
Interest.df$Interest1<-relevel(Interest$Interest1, ref='Somewhat Interested')
Interest.df$Interest1<-relevel(Interest$Interest1, ref='Very Interested')
Interest.df$Interest2<-relevel(Interest$Interest2, ref='News about Bangladesh')
Interest.df$Interest2<-relevel(Interest$Interest2, ref='Education')
[...]
Interest.df$Interest2<-relevel(Interest$Interest2, ref='European Politics')
detach(Interest)
attach(Interest)
### Finally create the graph in ggplot2 ###
library(ggplot2)
p<-ggplot(Interest, aes(Interest2, ..count..))
p<-p+geom_bar((aes(weight=Interest.weight, fill=Interest1)))
p<-p+coord_flip()
p<-p+scale_y_continuous("", breaks=NA)
p<-p+scale_fill_manual(value = rev(brewer.pal(5, "Purples")))
p
update_labels(p, list(fill='', x='', y=''))
Я был бы очень признателен за любые подсказки, приемы или подсказки.
3 ответа
О процентах от .. count .. , попробуйте:
ggplot(mtcars, aes(factor(cyl), prop.table(..count..) * 100)) + geom_bar()
, но, поскольку не рекомендуется вставлять функцию в aes () , вы можете написать пользовательская функция для создания процентов из .. count .. , округления до n десятичных знаков и т. д.
Вы пометили этот пост plyr , но я не вижу здесь действующего plyr , и держу пари, что один ddply () может с этим справиться. Электронной документации plyr должно хватить.
Если я правильно вас понимаю, чтобы исправить проблему с маркировкой осей, внесите следующее изменение:
# p<-ggplot(Interest, aes(Interest2, ..count..))
p<-ggplot(Interest, aes(Interest2, ..density..))
Что касается второго, я думаю, вы бы лучше работать с пакетом reshape . Вы можете использовать его для очень простого объединения данных в группы.
Ссылаясь на комментарий aL3xa ниже ...
library(ggplot2)
r<-rnorm(1000)
d<-as.data.frame(cbind(r,1:1000))
ggplot(d,aes(r,..density..))+geom_bar()
Возвращает ...
альтернативный текст http://www.drewconway.com/zia/wp-content/uploads/2010/04/de density.png
{kind=link}
Бины теперь имеют плотности ...
Ваш первый вопрос: Это поможет?
geom_bar(aes(y=..count../sum(..count..)))
Ваш второй вопрос; не могли бы вы использовать переупорядочивание для сортировки столбцов? Что-то вроде
aes(reorder(Interest, Value, mean), Value)
(только что вернулся из семи часов езды - устал - но думаю, это должно сработать)