Какие понятия статистики полезны для профилирования?
Я означал приводить в порядок определенное рисование кистью на моем знании статистики. Одна область, где это походит на статистику, была бы полезна, находится в профилировании кода. Я говорю это, потому что кажется, что профилирование почти всегда вовлекает меня пытающийся вытянуть некоторую информацию от большого объема данных.
Есть ли какие-либо предметы в статистике, на которой я мог повторить добраться, лучшее понимание профилировщика произвело? Бонусные очки, если можно указать на меня на книгу или другой ресурс, который поможет мне понять эти предметы лучше.
7 ответов
Я не уверен, что книги по статистике это полезно, когда речь идет о профилировании. Запуск профилирования должен дать вам список функций и процент времени, проведенного в каждом. Затем вы посмотрите на тот, который принял наибольшую процентную мудрую и посмотреть, сможете ли вы оптимизировать его любым способом. Повторите, пока ваш код будет достаточно быстрым. Не так много масштабов для стандартного отклонения или Chi в квадрате, я чувствую.
Статистика - это весело и интересно, но для настройки производительности вам это не нужно. Вот объяснение почему , но простая аналогия может дать идею.
Проблема производительности похожа на объект (который может быть фактически быть несколькими подключенными объектами), похороненные под акром снега, и вы пытаетесь найти его, прощупывая случайным образом с палкой. Если ваша палка бьет ее пару раз, вы нашли это - именно точный размер не так важен. (Если вы действительно хотите, чтобы лучше оценить, насколько велика, принять больше зондов, но это не изменит свой размер.) Количество раз, когда вы должны прозреть снег, прежде чем найти, зависит от того, сколько площади Снег это под.
Как только вы найдете его, вы можете вытащить его. Сейчас есть меньше снега, но при снегу может быть больше предметов. Так что с большим зондом вы можете найти и удалить их. Таким образом, вы можете продолжать идти, пока не сможете ничего не обнаружить, что вы можете удалить.
В программном обеспечении снег - это время, и зондирование предпринимает образцы случайных временных образцов стека вызовов. Таким образом, можно найти и удалить несколько проблем, в результате чего большие ускоренные факторы .
И статистика не имеет ничего общего с этим.
Я думаю, что самая важная статистическая концепция понять в этом контексте Закона Амдаля . Несмотря на то, что обычно упоминается в контекстах параллелизации, закон Amdahl имеет более общую интерпретацию. Вот выдержка с страницы Википедии:
более технически, закон обеспокоен со скоростью, достижимыми из улучшение к вычислению, которое влияет на пропорцию P этого вычисление, где улучшение имеет ускорение S. (например, если Улучшение может ускорить 30% от вычисление, р будет 0,3; если то улучшение делает часть затронутой частью в два раза быстрее, S будет 2.) Amdahl's Закон утверждает, что общий ускорение Применение улучшения будет
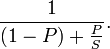
Все, что я знаю о профилировании, это то, что я просто читаю в Википедии :-) Но я знаю честную статистику. Артикул профилирования упомянул выборку и статистический анализ данных выборки. Очевидно, что статистический анализ сможет использовать эти образцы для разработки некоторых статистических утверждений о производительности. Допустим, у вас есть некоторая мера производительности, м, а вы обрабатываете эту меру 1000 раз. Давайте также скажем, вы знаете что-то о базовых процессах, которые создали это значение M. Например, если M - сумма куча случайных вариантов, распределение M, вероятно, нормально. Если M - продукт куча случайных вариантов, распределение, вероятно, логнормальное. И так далее ...
Если вы не знаете основное распределение, и вы хотите сделать некоторые утверждения о сравнении производительности, вам может понадобиться, что называется непараметрической статистикой.
В целом я бы предложил какой-либо стандартный текст по статистическому выводу (DENTROOT), текст, который охватывает разные распределения вероятностей и где они применимы (Hastings & Peacock), а также книга о непараметрической статистике (Conover). Надеюсь это поможет.
Зед Шоу, как обычно, имеет некоторые мысли на тему статистики и программирования, но он ставит их гораздо красноречивее, чем я мог бы.
Если вы примените метод программирования MVC с PHP, это будет то, что вам нужно для профилирования:
Приложение: Время настройки контроллера Время настройки модели Просмотр времени настройки База данных Запрос - Время Файлы cookie Имя - Значение Сеансы Имя - Значение
Я думаю, что одна концепция, связанная как со статистикой, так и с профилированием (ваш исходный вопрос), которая очень полезна и используется некоторыми (время от времени вы видите рекомендуемый метод), заключается в выполнении «микропрофилирования»: многие программисты будут сплотиться и вопить «вы не можете микропрофилировать, микропрофилирование просто не работает, слишком многое может повлиять на ваши вычисления» .
Тем не менее, просто запустите n раз ваше профилирование и сохраните только x % ваших наблюдений, те, которые находятся около медианы, потому что медиана является «надежной статистикой» (в отличие от среднее значение), на которое не влияют выбросы (выбросы - это именно то значение, которое вы не хотите принимать во внимание при выполнении такого профилирования).
Это определенно очень полезный статистический метод для программистов, которые хотят микропрофилировать свой код.